
【深度学习】CycleGAN开源项目学习笔记 | 完整流程 | 报错总结 | pytorch
【深度学习】CycleGAN开源项目学习笔记 | 完整流程 | 报错总结 | pytorch
文章目录
前言
你敢想象,就是这么一个简单的开源网站,我居然调了一天才通(毕竟是第一次,一些比如visdom,命令行的参数第一次接触到)
本文所使用的开源项目网址:https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix
一、下载项目,文件结构观察
下载项目完成后,我们看看内部的结构:

据说后面很多开源项目都是按照这个格式来的(大致格式)
二、数据集下载
在ReadMe里面已经提到了数据集下载方式:

但是这里的bash命令一直没有运行成功,所以换用其他方法:
我们打开dataset文件夹:

用记事本打开里面的cyclegan的sh文件,把这行网址复制粘贴(最后一个反斜杠后面的内容删除):

打开网址,选择你想要的数据集,这里我们的实验选择斑马horse2zebra数据集:

解压之后,把数据集粘贴到datasets下面:

斑马数据集内部长这个样子,后面如果要自己制造数据集也是这样搞:

三、训练
3.1、训练初体验
训练前,看看自己的环境是不是安装好了,尤其是visdom这个可视化库。没用过的话建议先用用看,试一试,防止后面出问题找不出来错误。
在开始训练前,需要打开visdom,在命令行直接输入以下命令:
python -m visdom.server

点击下面的8097网址进去:

下面就是比较关键的,输入训练指令,Readme里面也给出了比较清楚的指令(不过我们需要进行修改):
python train.py --dataroot ./datasets/maps --name maps_cyclegan --model cycle_gan
我们来解释一下,这三个需要导入的参数分别是什么:?
1)datasets 这个最简单,就是数据集的路径
2)name 这里指的是保存训练权重的文件夹的名字。在开始训练后,文件夹里会生成一个checkpoints子文件夹,用来保存权重文件:

而打开后就是我们命名的文件夹:

里面的权重文件长这样:

web里面放着训练过程
3) model:这个顾名思义就是训练的模型是啥,这个开源项目的模型如下(在model文件夹里):

在命令行里输入cycle_gan后 程序会自动加上_model
介绍完之后,我们来更改
python train.py --dataroot ./datasets/horse2zebra --name horse2zebra --model cycle_gan
我们在命令行里面运行,不出意外的话,意外就来了:

报错内容:module ‘torch._C’ has no attribute ‘_cuda_setDevice’
在网上查找资料说,这是因为环境里pytorch下载的CPU版本导致的。但是我环境里明明是GPU版本呀,这里有可能是因为CMD命令行识别环境错了,所以我们换在anaconda里面运行:

记得要激活自己的GPU环境,同时切换到文件路径,再输入命令后:


这里开始,训练就正式开始了,训练可视化可以在visdom里面看:

3.2、命令行输入参数
我们在3.1中输入到命令行的参数为:
python train.py --dataroot ./datasets/horse2zebra --name horse2zebra --model cycle_gan
也就三个。其实事实上能输入的不止这些,还有很多其他参数也是可以输入进去的:

在train_options这个py文件中,存在大量的add_argument,这些参数都是可以输入的,且有文字描述,帮助大家理解它们是用来干啥的。
3.3、继续训练命令
比如我昨天训练了15个epoch,今天我想继续训练,可以在命令行中输入下列指令:
从图片中我们可以看到,继续训练的开关被打开了


但是它画图依然是从1epoch开始画的,而不是从我停止训练的15epoch,不知道有没有大神能够指点一下

四、预测
4.1、使用自己训练完的权重文件进行预测
这里我自己训练了15轮,权重文件保存在checkpoint里:

我们在anconda命令行里输入:
python test.py --dataroot ./datasets/horse2zebra --name horse2zebra --model cycle_gan
结果会保存在results 文件夹里:



打开html我们看看效果:

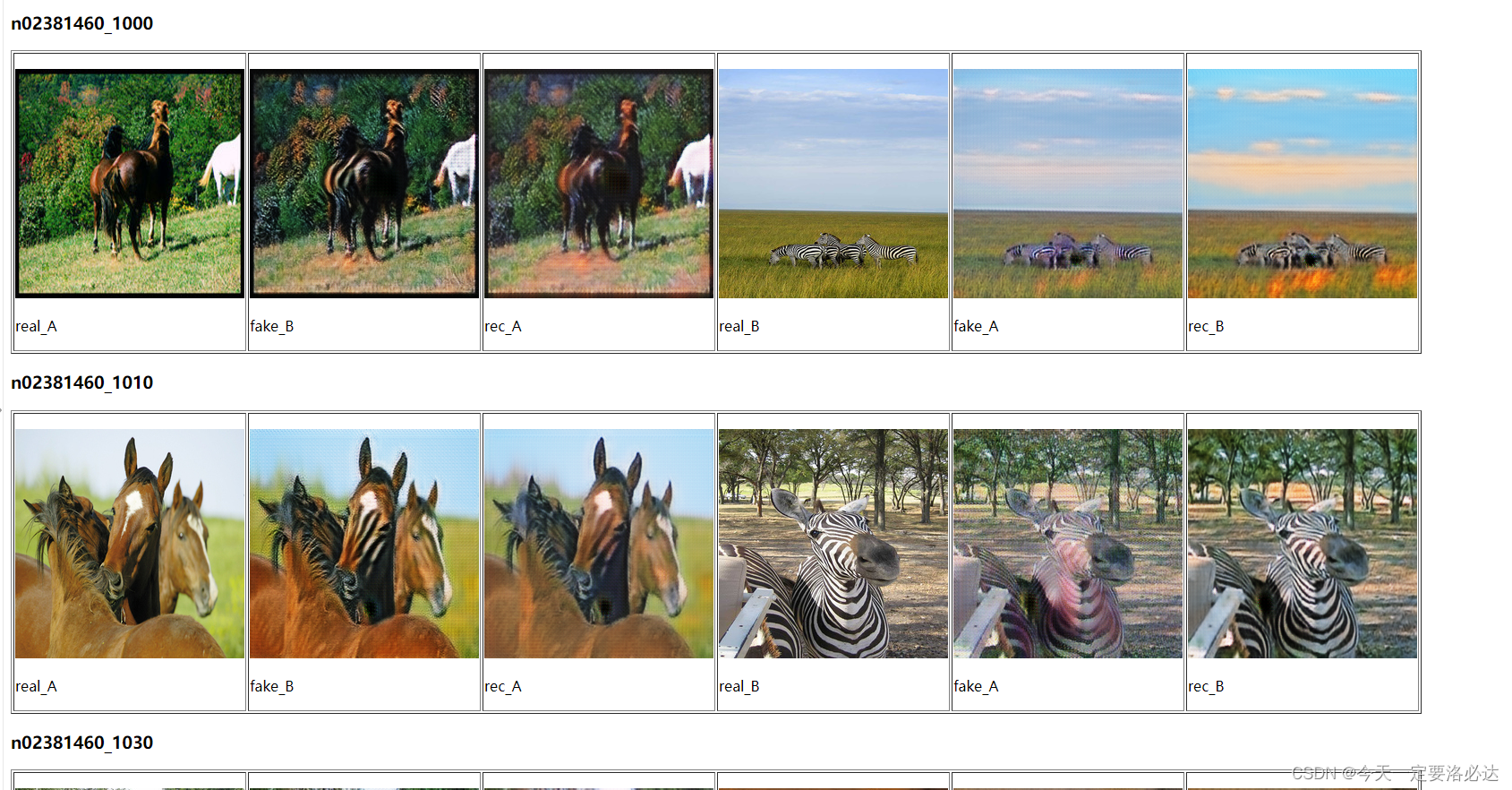
15轮的效果还是一般 轮数没训练够
4.2、使用网上的预训练文件进行预测
首先我们需要在网上下载预训练权重文件:预训练文件

下载完毕后,在check_points文件夹里面新建一个文件夹:horse2zebra.pth_pretrained:

将刚刚下载的预训练权重重新命名为:latest_net_G.pth:

这时候的准备工作已经完成了,此时打开anconda 激活环境 切换路径,输入下列指令:
python test.py --dataroot datasets/horse2zebra/testA --name horse2zebra.pth_pretrained --model test --no_dropout
此时就开始预测了:

预测完成后可以在根目录下的results文件夹中找到结果:

载打开里面的文件夹可以看到

打开html:

可以看到效果明显比我自己训练的好(毕竟我才训练了15轮)

更多推荐

 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)