
〖3D激光点云〗深度学习点云知识!
激光雷达点云bin文件读取和显示!文章目录一. 背景知识1.1. 视觉任务1.2. 激光雷达(Lidar)1.3. Lidar数据的特点二. 深度学习处理点云的方法2.1. 深度学习处理点云的方法首先声明文章主要参考:陈亮—深度学习点云!一. 背景知识1.1. 视觉任务深度学习在视觉感知任务中大放异彩。一些自动驾驶的公司在视觉感知领域取得的不菲成绩,例如下面的交通标识牌检测、车道线检测、人的bou
·
| 激光雷达点云bin文件读取和显示! |
文章目录
首先声明本文章内容主要参考B站:
一. 背景知识
1.1. 视觉任务
深度学习在视觉感知任务中大放异彩。
一些自动驾驶的公司在视觉感知领域取得的不菲成绩,例如下面的交通标识牌检测、车道线检测、人的bounding box检测、人的关键点检测、车辆的检测、车辆3D bounding box的检测、车辆的距离、和速度的估计等等。



1.2. 激光雷达(Lidar)
左下方图是64线激光雷达以及它的数据渲染的图,可以看到一个一个的圆,有一些不同的颜色,分别表示它们反射的强度。右边是雷达的工作照,工作中它在不停的旋转,为什么激光雷达工作中不停的旋转,为什么数据中有一个一个的圆呢?这个还要介绍一下激光雷达的结构讲起。

【激光雷达与摄像头,未来哪种会成为自动驾驶的核心传感器呢?】 激光雷达数据简单但精确,适合做几何感知。视觉数据丰富但多变,适合做语义感知。在高级别自动驾驶里,无论是从优势互补还是传感器冗余的角度,二者缺一不可。
目前市面上能买到的激光雷达大概分为2类,一种是机械式Lidar,一种是扫描式Lidar。 下面简要介绍。
- 下图为机械式Lidar的拆解图

- 下图为旋转式Lidar的效果,不容的颜色表示激光雷达不同的反射强度,反射强度主要取决于被扫描物体的材质。例如白色的车道线反射强度比较高。

- MEMS式激光雷达。

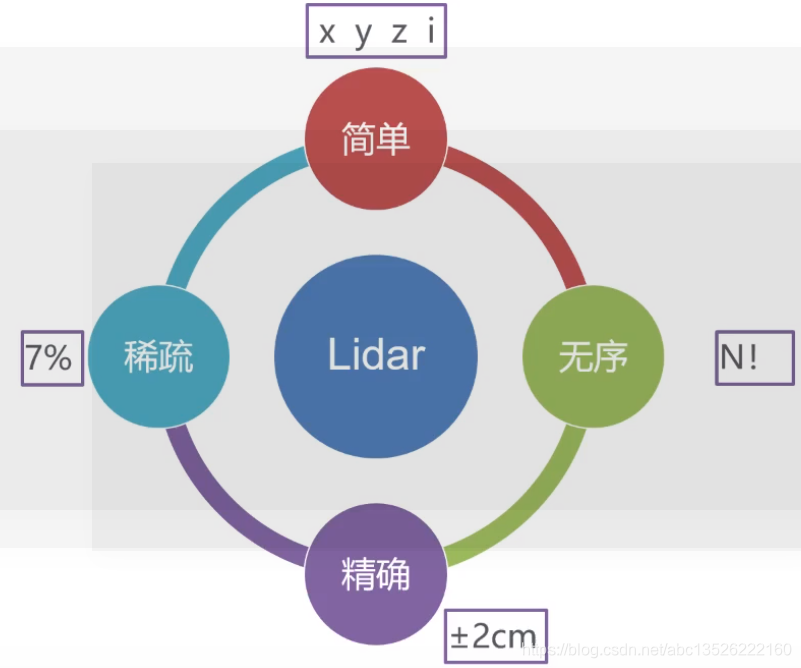
1.3. Lidar数据的特点
- i i i 表示反射强度。之前大概在KITTI数据集上面做了一个统计,把点云经过标定后,投影到图像上大概之后7%左右的像素才有雷达数据,这表明激光点云特别的稀疏。而且点云是无序的,这里 N N N 个点有 N N N 的阶乘个组合方式。
二. 深度学习处理点云的方法
2.1. 几类方法
深度学习处理点云数据方法:
- Pixel-based: (点投影到平面上,用2D CNN处理)。
- Voxel-Based: 类似于图像一样,图像是二维的把其进行栅格化,变成一个一个的像素。三维的我们也可以进行栅格化变成一个一个的体素(就是一个个小的立方体)。采用3D CNN进行处理。

- Tree-Based
- Point-Based: 更直接的方法,直接对点进行操作。输入 n × 3 n×3 n×3 的向量直接送入网络中, n × 3 n×3 n×3 的向量直接送入网路会有什么问题呢?我们知道深度学习中的方法要求数据的维度尽可能一样,要是不一样可能很难处理。比如做 b a t c h batch batch 处理的过程中,有可能一次送入 100 100 100 张图像,有些网络可能对输入的大小不敏感,但是在过批处理的过程中一般要求图像数量是一样大的。这里我们在处理点云数据也是一样的,如果我当前这个点云有 100 100 100 个点,下一个点云有 1000 1000 1000 个点,那么不同个数的点送入网络中,如何保证出来的东西是一样的呢?此外刚才提到的,这 100 100 100 个点有 100 100 100 中排列组合方式,如何保证网络对这些点的顺序不敏感呢?
- 这里重点介绍一下针对这 2 2 2 个问题(点的无序,点的维度(个数)不一样),PointNet是如何解决的。 基于这个思路可以设计更多更多的处理点云的网络。首先对于无序的这个问题的解决: 数学里有一类函数叫做对称函数,意思就是一串数据输入一个结果,如果输出的这个结果对输入的属于顺序不敏感(比如加法是一个对称函数)。Deeplearning中maxpooling是一个对称函数,不管里面的顺序如何,我只要最大的。下面网络结构图中 n × 3 n×3 n×3 的输入一直到 n × 1024 n×1024 n×1024 的输出,随后通过一个maxpooling变成了1024,这个maxpooling干了一个什么事情?就是在特征维度维度上做了一个pooling,把这个特征归一化到了一样1024维,而不取决于你输入的这个 n n n 的多少,所以maxpooling这里就是起到一个对称函数的作用,它把点的无序和点的个数问题都解决了。
- TNET是解决了点云旋转的问题,使用的maxpooling作为对称函数解决了点云的无序性。最后得到的global feature 就代表这个点云具有的特征,然后可以利用这些特征做一些分类操作之类。看下图:如果把全局的特征放在这,把 n × 64 n×64 n×64,它是每个点的 64 64 64 维特征,我把每个点的64维特征再加上global feature,我们可以得到每个点既有local的特征,又有全局的特征global feature,所以它考虑了局部和全局的关系。这样去做一个应用的话,我们可以对 n n n 进行一个分类,可能分出来 m m m 类,逐点分类的过程也就是语义的点的分割的方法。
- 看下图:基于PointNet可以做3类事情,我可以用这个点的全局特征告诉您这个点是什么物体。我们也可以利用这些点去做一个逐点的分类,每个单独的点是属于哪一类的。这里如果我们是针对所有点的逐点分类,那就是逐点的segmentation,如果是针对部分点的分类,类别的个数小于点的个数,那就是part segmentation(也就是把一个物体的几个部分单独分出来)。


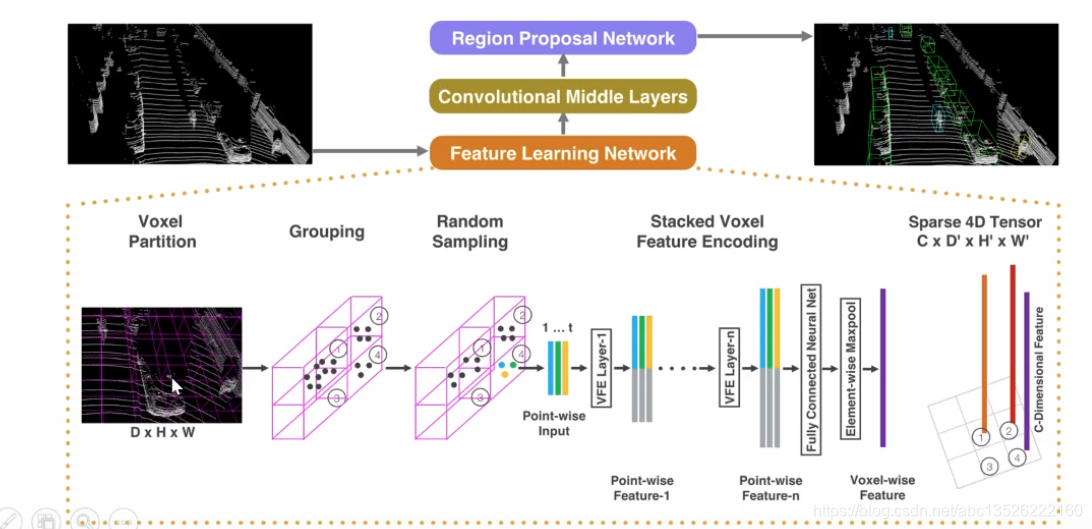
- 还有一篇可以做local和global的集大成者的文章,把前面这些文章都融合到一起的,这篇文章是VoxelNet。输入是一堆点云,体素分割的方法,把三维的世界分割成一个一个的小体素。这个体素根据不同的任务,比如做车辆检测,这个体素可以分的大一点,我做行人检测,这个体素可以分的小一点。
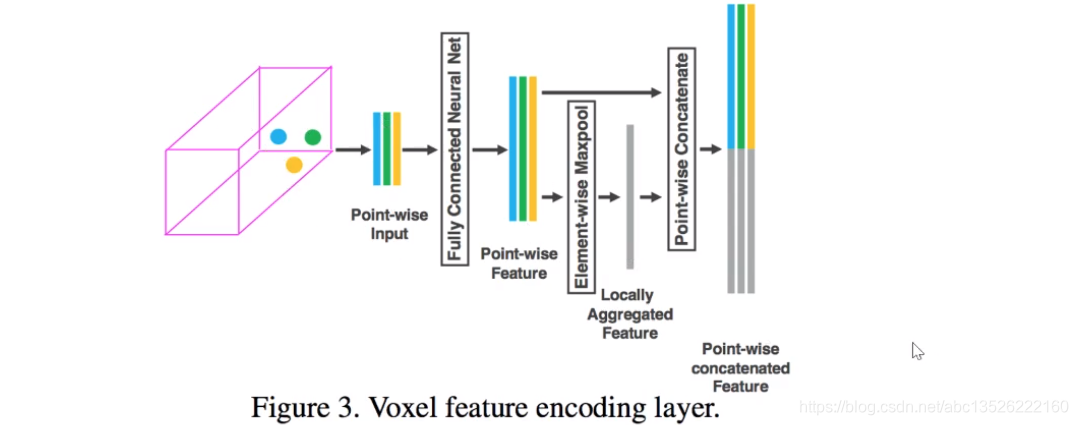
- 对于每一个体素格,有好多个点。对于每个点可以用类似于PointNet的方式提取全局特征global features和局部特征(可以看上面PointNet结构图)local features。实际上它把逐点的特征和整个点云的特征连接在一起,然后经过逐层的抽样,抽样出一个128维的一个体素的特征。因为我们这里的体素本身就是3维的了,每个体素上又有一个高阶的向量,所以最后形成一个4维的Tensor。这里注意不是每个体素都有点的,所以它是一个稀疏的,针对这个问题的话,我们又进行了一些卷积的操作,把稀疏的Tensor逐步的降低纬度,降低到原图大概1/4的时候,我们做一个RPN,从里面这些点以及点的特征里面去抽取出3D box 的proposals,这个proposals刚才在介绍第2篇文章的时候基本上已经介绍了,这篇文章其实是把所有文章的idea结合在一起。
2.2. 点云数据(database)
- 以上介绍的都是深度学习中处理点云的方法,做深度学习离不来数据。以上介绍的几种方法数据源基本来自以下方法,

- 数据仿真



更多推荐


 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)