
深度学习——(11)Knowledge distillation理论
知识蒸馏将已经训练好的模型包含的知识,蒸馏到另一个模型中teacher 模型只在训练的过程中使用一个teacher可以用于蒸馏多个studentloss分为两个部分第一部分称为Lsoft:(两个分布之间的loss)第二部分称为Lhard:(两个确定值之间的loss)
·
深度学习——(11)Knowledge distillation理论
文章目录
1.基本思想
将已经训练好的模型包含的知识,蒸馏到另一个模型中
2. 关键点
- teacher 模型只在训练的过程中使用
- 一个teacher可以用于蒸馏多个student
- 模型的参数量和捕获的知识之间并不是稳定的线性关系,而是接近边际收益逐渐减少的增长曲线
- 使用完全相同的模型架构和模型参数,使用完全形同的训练数据,可以捕获到的知识量并不一定完全相同,有一个关键的因素是——训练的方法
3. 知识蒸馏的理论依据
- 原始模型(teacher)要求:输入x可以相应的输出y。其中y经过softmax映射后,输出值对应的概率值
- 精简模型(student)训练:对于输入x可以输出y,其中y经过softmax后输出相应类别的概率值
4. 知识蒸馏训练过程和传统的训练过程
- 传统:对ground truth求极大似然
- 知识蒸馏:用老师的分类概率作为soft target
5. softmax
原始:
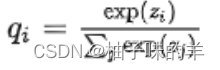
增加温度:
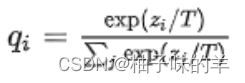
6.知识蒸馏过程
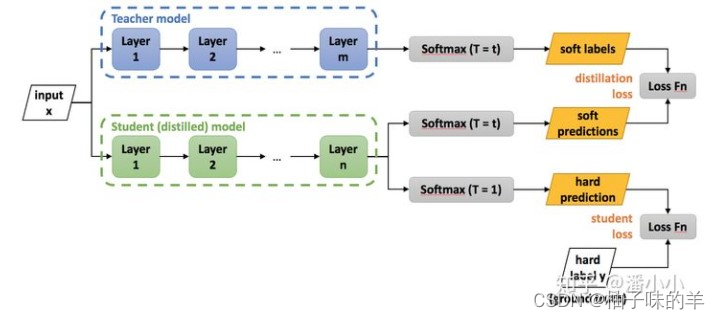
其中的loss分为两个部分
- 第一部分称为Lsoft:表示teacher模型得到的特征softmax的分布 与 student模型得到的特征softmax的分布之间的crossentropy-(两个分布之间的loss)
- 第二部分称为Lhard:表示student模型得到最终的预测值(最终的label,不是上面得到的probability)与ground truth之间的crossentropy(两个确定值之间的loss)——使用该loss的原因:有时候teacher也会出现错误,使用学生预测的值和真实值计算loss,可以有效降低错误传播给学生(有效避免老师对学生的误导)
最终loss :
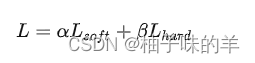
7. 蒸馏过程中的温度
原始的softmax是温度为1 时候的特立,当温度大于1的时候,概率分布较为平缓,但是当温度小于1的时候,概率分布就很陡峭
**温度的高低衡量的是 在学生网络训练过程中对负标签的关注程度。**温度较低时,对负标签的关注,尤其是那些显著低于平均值的负标签的关注较少,但是当温度较高时,负标签相关的值会相对增大,学生标签会相对更多关注负标签
一般温度如何选择??
- 从有部分信息量的负标签中学习——>温度要高一些
- 防止受到负标签中噪声的影响——>温度要低一些
下午写一下代码,晚点发!

更多推荐


 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)