
23-10-11月深度学习论文阅读总结与启发
对于某个特定的神经网络模型来说,模型除了神经元内部参数,以及神经元之间的权重之外,模型的规模、结构完全不会变化,这也是计算机存储结构等因素决定的。当前深度学习的研究对神经科学研究的存在的必要性提出了挑战,因为二者研究的目标都是对于人类大脑的工作原理的研究,但是深度学习偏向于应用、结果论,而神经科学则重点探究原理和过程。这种由AI生成的肿瘤图像来训练AI,在数据集的角度上显然是扩充了数据集的规模,增

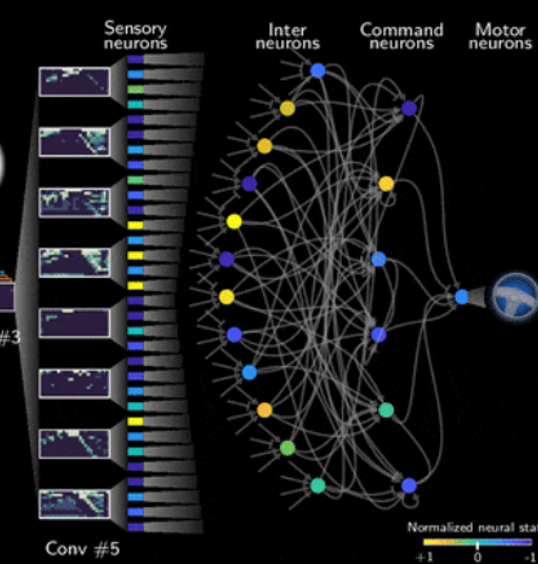
一、Nature杂志:19个神经元实现自动驾驶:
Neural circuit policies enabling auditable autonomy | Nature Machine Intelligence
1、关于可解释性的思考:
如果想要解决神经网络中的可解释性的问题,在现有的经典模型来看,如果不加以改进模型结构,增加一些可视化的“部件”或“工具”,传统神经网络的“黑盒”问题将完全不可解。因为只是在一堆神经节点的数据以及神经元之间连线的权重中找到新的科学知识是不可能的,“黑盒”是不可打破的。只有研究新的神经网络结构,添加一些可解释性的“部件”,才有希望看到“黑盒”的内部。
2、关于创新和启发的思考:
这篇Nature从线虫这样原始的生物中得到启发,创造出这样一个史无前例的神经拓扑结构,其他研究者们也应该从生物学寻找启发,创造出新的神经网络,对“黑盒”发起冲击。
研究方向可以从简单生命的神经系统出发,研究神经元连接的作用机制,再对人工神经网络模型进行改进。现在的神经元连接比真实的人类脑神经相差甚远,通过改进现有的神经网络模型使之更加贴合人类大脑机制,可能是一个神经网络技术突破的关键。
3、关于现有神经网络与生物神经系统差异的思考:
现有的神经网络模型无一不是先对数据进行学习,之后通过反向传播算法对神经元之间的权重进行修改这样的模式。对于某个特定的神经网络模型来说,模型除了神经元内部参数,以及神经元之间的权重之外,模型的规模、结构完全不会变化,这也是计算机存储结构等因素决定的。
但是从仿生学的角度来讲,生物的神经系统随着个体的成长是在不断地变化、扩大的。生物个体从外界获取到的知识,让个体的神经系统增添新的神经元以及建立神经元之间新的突触。即使是成年个体,神经系统已经发育完全,也不代表神经系统完全不会更新。所以设计一个可以“发育”、“成长”、“自我更新”的神经网络,我认为是一个目前有发展前景的方向。
对于这一思路的实现的阻碍,第一在于计算机系统和数据存储结构的设计,对于这一点,需要对这种“自我发育”的神经网络的规模进行评估,避免计算机存储空间占满。而数据结构则必然会采用链式存储结构(相对于顺序存储来说,增添和删除神经元数据更加灵活),而目前的神经网络模型的源代码使用的基本都是顺序存储的数组张量,所以算法也需要进行修改以及创新。第二个难点在于神经科学和脑科学原理,在何时神经系统应该进行“生长”,又应该在何处进行新的神经元的连接?而这些“生长”、连接的作用和意义又在哪里,为什么要在这里连接而不是在那里?这些问题本质上都是神经科学和脑科学的亟待解决的课题。
综上,为了设计出可以“自我发育”的神经网络模型,在神经科学和脑科学领域也需要做出研究学习。而我们研究者则可以从神经系统简单的生物研究学习(而现在神经科学研究者们也是这样做的),就像这篇文章所做的一样。
4、液态神经网络:
液态神经网络相较于离散数据式的神经网络而言,具有数据传输的延迟性,能更好的模拟真实的生物神经网络。
5、NCP19神经元在几个方面优于其他的神经元包括:
(1)在不断输入扰动下(需要干预)做出正确决策的鲁棒性更好。
(2)在有输入噪音情况下模型的输出的鲁棒性更好。
(3)神经活动更加平滑,意味着驾驶技术更稳定。
6、关于提高神经网络的可解释性问题:
文章同样提到要设计新的神经网络架构来提高可解释性(可以从语义方面或学习过程方面),但是不管是哪种方式,只要神经网络的规模上去了,可解释性都会大幅降低,因为本质上神经元内部都是数据,数据不具有自解释性。
而本文通过19个神经元的设计,自然具有更多透明性。
7、NCP中各个神经元在进行左右转或直行时的激发程度是不一样的。如某个神经元只在左转时激发,某个在直行时激发。
联想到大脑的功能分区,如恐惧和快乐的情绪大脑不同区域的激活程度也有所不同。
这篇研究表明,解决现实生活中的复杂问题不一定要使用非常庞大的神经网络模型。
二、重庆邮电大学校长 高新波教授 ———关于人工智能未来发展分析的探讨
重庆邮电大学校长高新波教授:人工智能未来发展趋势分析_网易订阅 (163.com)
1、人工智能目前没有体现“聪明”的特性,而是体现出“勤奋”的特性:
目前人工智能训练往往需要大量的数据集来进行训练,规模经常为上亿级别,这样的数据集远远超过一个普通人学习所需要的训练量。可见人工智能并没有想象中那么聪明。
2、未来AI的发展方向应该是做“减法”而不是做“加法”。
(一方面构建更为灵巧的网络模型,通过轻量化的模型降低对数据量和算力的需求;另一方面,构建更为高效广泛的共享复用机制。)
这与我前一篇Nature文章所讨论的一致,构建一个相对小型的、性能更好的神经网络是现在重要的发展方向。
同时,对于通过较少数据来训练神经网络以达成训练目标的研究也需要同步进行。
3、通过知识和数据双驱动的人工智能:
第一代通过知识驱动的人工智能往往具有更好的可解释性和算法效率,但是该方向发展的难点在于将专家的知识转变为人工智能算法。(深蓝击败卡斯帕洛夫)
第二代人工智能也就是通过深度神经网络训练出来的人工智能。优点在于其准确性高(有时候可以超越人类),缺点是鲁棒性差、可解释性差并且需要大规模的高质量标记数据集,非常脆弱。
清华张钹教授提出的第三代人工智能,通过知识、数据双驱动的AI。目前在垂直行业发展良好,但是对于知识、数据双驱动的通用型人工智能(AGI)的研究还颇具挑战。
4、人机物混合的人工智能:
人在回路中(human-in-the-loop)指的是人作为智能回路的一个决策或者计算节点,构成的人工智能
人在回路上(human-in-the-loop)指的是将人的认知系统加入到人工智能内部。
5、可信可靠可解释的人工智能:
可解释性人工智能有三大需求:第一是使深度神经网组件变得透明;第二是从深度神经网里面学习到语义图;第三是生成人能理解的解释。
6、深度森林:
基于逐层加工处理、内置特征变换和模型复杂度三个关键因素设计出了深度森林可代替深度神经网络。深度森林,训练简单效率高,可作为非深度神经网络的一个尝试
7、宽度神经网络:
取代深度为宽度,大大减小了计算量,但是目前适合用宽度的数据特征较少。
8、自适应人工智能:
如我文章一提到的可以自我进化的人工智能。训练出来的模型不可能知道所有的情况,因此模型需要对环境中的其他不确定情况进行学习、适应,这也是未来的发展趋势。
总结:综合以上几点,未来人工智能的发展的方向,应该向着轻量化、类人化、高效化方向发展,并且期待着小型的、可解释的、训练成本低的模型的出现。

三、Nature期刊:深度学习与神经科学
If deep learning is the answer, what is the question? | Nature Reviews Neuroscience
文章认为深度学习可能会给神经科学带来颠覆性的理论,进而共同促进深度学习和神经科学的发展
1、深度学习中的许多结构与生物神经中的结构有相似之处。
目前可以得到推论:人类和其他动物的复杂行为和结构化的神经表征可能起源于有限的计算原则。
2、目前灵长类动物神经皮层与CNN、RNN所展现出来的结果具有高度相似性:

3、神经网络的设计缺乏一个系统的原则性的设计指导:
大多数神经网络模型的设计都是盲目的,结果论的。例如专家发布了一个新型的深度神经网络,增加了某些层,做出来的实验结果会更好,但是专家并不能说明这其中的原因。很少基于生物合理性来设计神经网络。
文章提到,如果神经网络的设计能够更多的基于生物大脑来设计,例如增加循环链接和类似丘脑的前端视网结构,可以更加符合现实的编码特性。
而深度学习网络的这种基于系统效能,而不是系统有效的原因的设计思路,也导致了深度学习的可解释性差和“黑盒”问题。
而基于生物合理性的设计又经常在准确度方面欠缺。在深度学习上基于生物合理性的设计难以准确映射到模型的准确性和效率上。
4、对于深度学习对于神经科学研究的冲击和存在问题挑战的思考:
当前深度学习的研究对神经科学研究的存在的必要性提出了挑战,因为二者研究的目标都是对于人类大脑的工作原理的研究,但是深度学习偏向于应用、结果论,而神经科学则重点探究原理和过程。
所以文章提出,当前神经科学研究者应避免将深度学习对神经科学指导辅助研究。
本质上,这两个研究方向都是为了研究大脑等高级神经系统的原理。但是深度学习对此是先构建一个类似于大脑功能的计算机模型,直到模型拥有与大脑相同的效能时,该模型即为大脑模型。
而神经科学则是直接从大脑出发,探究各个神经元之间的联系以及作用,从而可以构建出一个具有相同功能的“人造大脑”来指导人类生活。
深度学习框架最终应该为神经系统研究者提供一个神经系统框架的假设集,以供神经研究者研究。而深度学习的最终框架(最强大版本),也应该基于现有的神经科学研究。
5、声称深层网络和大脑等效表示的里程碑式研究实际上使用了未经梯度下降训练的深层网络
更严格的更系统的,评估深层网络和生物大脑以相似方式学习,是未来深度学习应该重点研究的方向。
可以测量神经信号是否是模型激活的线性变换。对于这一点,即便神经系统和神经网络模型的规模有很大差异,也依然存在这样的相关性。
总结:这篇文章主要讲了生物神经系统和深度学习神经网络的一些相关性以及提出了一些结合生物神经和神经网络发展的方向。
启发:当代神经网络如果想要有重大发展,必须结合大脑或者高级生物神经系统等交叉学科进行。因此,对于脑科学,神经科学以及认知科学的学习也就变得十分重要。

四、通过AI生成肿瘤图像数据集,减少人工标注工作量
源码 GitHub - MrGiovanni/SyntheticTumors: [CVPR 2023] Label-Free Liver Tumor Segmentation
文章 arxiv.org/pdf/2210.14845.pdf
对于深度学习识别癌细胞,一个肿瘤的数据集的收集十分困难,可能需要花上数年时间,人工成本和时间成本都很高。于是,这篇论文另辟蹊径使用生成式AI,主动地合成肿瘤图像(无标签),并且可以主动调整合成的肿瘤的纹理、大小等参数,从而极大地扩充了现有的数据集。这具有着非常巨大的研究前景。
1、效果如何:
论文研究的方法生成的肿瘤图像的形状和质地很真实,医生也难以区分。在以后的神经网络识别癌细胞的研究中可以发挥积极的作用。
2、使用合成图像训练的成果:
文章提到:使用真实的肿瘤图像数据训练的模型与使用AI合成图像训练的肿瘤在实际测试中的效果相似。
但是当两个模型遇到直径为10mm左右的小肝脏肿瘤时则出现了差别。使用真实图像训练的模型表现得更好。
作者预期,这是因为合成图像训练没有重点训练小肿瘤的合成图像,调节合成的图像参数从而合成更多小肿瘤的图像提供训练,很可能会达到真实图像训练的效果。
3、我的思考:
这种由AI生成的肿瘤图像来训练AI,在数据集的角度上显然是扩充了数据集的规模,增添了图像数据的丰富性——毕竟生成的图像可以对肿瘤的大小、质地、纹理都直接进行操控。
但是从直觉上,AI生成的肿瘤图像毕竟不是真实的图像,而这些图像会再成为数据重新交给AI识别训练,这样的训练流程有可能导致一些不可知的后果(毕竟我们不能够100%确定一个肿瘤的类别,所以还是存在一些黑盒的)。可能会伴随一些细微特征的缺失,迭代过程中出现准确度下降的问题。这些都是亟待研究的问题。

更多推荐


 23
23 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)