
论文篇 | 基于深度学习的机器翻译论文总汇
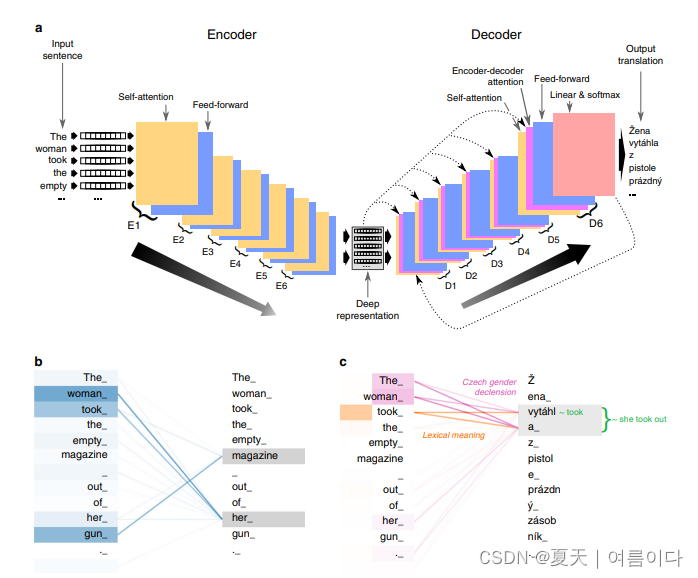
长期以来,人们一直认为人类翻译的质量对于计算机翻译系统来说是无法实现的。在这项研究中,我们提出了一个深度学习系统CUBBITT,它挑战了这一观点。在人类法官的上下文感知盲测评估中,CUBBITT在保留文本含义(翻译充分性)方面显着优于专业机构的英语到捷克语新闻翻译。虽然人工翻译仍然被评为更流畅,但CUBBIT被证明比以前最先进的系统更流畅。此外,翻译图灵测试的大多数参与者都很难将CUBBITT翻译
本文主要是通过粗略阅读论文,了解基于机器翻译的idea的实现。
机器翻译是将源语言中的句子翻译成不同目标语言的任务。机器翻译的方法可以从基于规则的到基于统计的到基于神经的。最近,像 BERT 这样的基于编码器-解码器注意力的架构在机器翻译方面取得了重大改进。用于对机器翻译系统进行基准测试的最流行的数据集之一是 WMT 系列数据集。机器翻译系统最常用的一些评估指标包括 BLEU、METEOR、NIST 等。(所有论文标题与参考文献相对应)
1.2020-Transforming machine translation: a deep learning system reaches news translation quality comparable to human professionals
转变机器翻译:深度学习系统可达到可与人类专业人士相媲美的新闻翻译质量
摘要:
长期以来,人们一直认为人类翻译的质量对于计算机翻译系统来说是无法实现的。在这项研究中,我们提出了一个深度学习系统CUBBITT,它挑战了这一观点。在人类法官的上下文感知盲测评估中,CUBBITT在保留文本含义(翻译充分性)方面显着优于专业机构的英语到捷克语新闻翻译。虽然人工翻译仍然被评为更流畅,但CUBBIT被证明比以前最先进的系统更流畅。此外,翻译图灵测试的大多数参与者都很难将CUBBITT翻译与人工翻译区分开来。这项工作接近人工翻译的质量,甚至在某些情况下充分超越了它。这表明深度学习有可能在以保护意义为主要目标的应用中取代人类。
2.2016-Neural Machine Translation by Jointly Learning to Align and Translate
摘要
神经机器翻译是最近提出的一种机器翻译的方法。与传统的统计机器翻译不同,神经机器翻译的目的是建立一个单一的神经网络,可以共同调谐,以达到机器翻译的目的。翻译的目的是建立一个单一的神经网络,该网络可以被联合调整,以最大限度地提高翻译性能。最近提出的神经机器翻译模型通常属于编码器-解码器家族,并将源句编码为一个固定长度的向量,解码器从中生成一个翻译。在本文中,我们猜想,使用固定长度的矢量是提高性能的一个瓶颈。在提高这种基本的编码器-解码器架构的性能方面是一个瓶颈,并建议通过允许一个模型自动(软)搜索来扩展这一架构
延伸,允许模型自动(软)搜索源句中与预测目标词相关的部分,而不需要将这些部分形成一个硬性的目标词。而不需要明确地将这些部分形成一个硬段。有了这种新方法。我们实现了与现有的最先进的基于短语的系统相媲美的翻译性能。基于短语的系统在英法翻译任务中的表现。此外。定性分析显示,该模型发现的(软)对齐方式与我们的直觉一致。
实现代码:https://github.com/alex-berard/seq2seq?utm_source=catalyzex.com
3.2019-Korean-to-Chinese Machine Translation using Chinese Character as Pivot Clue
摘要:
韩语-汉语是一种资源匮乏的语言对,但韩语和汉语在词汇方面有很多共同之处。可以转换成对应汉字的汉韩单词占整个韩语词汇量的五十多个。受此启发,我们提出了一个简单的语言动机解决方案,通过使用它们的常用词汇来提高韩语到中文神经机器翻译模型的性能。我们以汉字为翻译支点,将韩语句子中的中韩词转换为汉字,然后以转换后的韩语句子为源句训练机器翻译模型。韩语到汉语翻译的实验结果表明,采用该方法的模型将翻译质量提高了 1 倍。
4.2020-Very Deep Transformers for Neural Machine Translation
摘要
我们探索了非常深的 Transformer 模型在神经机器翻译 (NMT) 中的应用。使用一种简单而有效的初始化技术来稳定训练,我们表明构建具有多达 60 个编码器层和 12 个解码器层的标准基于 Transformer 的模型是可行的。这些深度模型的性能比其基线 6 层模型高出 2.5 BLEU,并在 WMT14 英语-法语(43.8 BLEU 和 46.4 BLEU 带回译)和 WMT14 英语-德语上实现了新的最先进的基准测试结果(30.1 BLEU)。代码和经过训练的模型将在以下位置公开提供:https://github.com/namisan/exdeep-nmt。
5.2020-Korean Neural Machine Translation Using Hierarchical Word Structure
摘要
韩国的神经机器翻译可能会明显受到低资源问题的困扰。因此,我们提出了一种增强方法,它充分地利用了源表示法中的分层韩语词汇嵌入结构的方法。据我们所知,这是对此类韩语NMT的首次尝试。每个韩语单词都可以被分解成字符和Jamo级(子字符)单元。因此,我们合并了
字符级和句子级表征与单词嵌入相结合来捕捉重要的组合词的意义。然后,合并后的的表征被送入NMT模型。我们简单与基于词的NMT基线相比,我们简单而新颖的方法实现了BLEU的提高(最高可达0.6)。与基于词的NMT基线相比,在韩语到汉语和韩语到英语的翻译任务中,我们简单而新颖的方法取得了BLEU的提高(高达0.6)。


6.2020-Decoding Strategies for Improving Low-Resource Machine Translation
摘要
预处理和后处理是自然语言处理 (NLP) 应用软件的重要方面。神经机器翻译 (NMT) 中的预处理包括子词标记化以缓解未知词的问题、仅过滤适合训练的数据的并行语料库过滤以及确保语料库包含足够内容的数据增强。后处理包括自动后期编辑和翻译过程中解码过程中各种策略的应用。最近的 NLP 研究基于预训练微调方法 (PFA)。然而,当硬件不足的中小型组织尝试提供 NLP 服务时,往往会出现吞吐量和内存问题。当使用 PFA 处理低资源语言时,这些困难会增加,因为 PFA 需要大量数据,而低资源语言的数据往往不足。利用当前的研究前提,即在不改变模型的情况下,可以通过各种预处理和后处理策略来增强 NMT 模型的性能,我们将各种解码策略应用于依赖低资源语言对的韩语 - 英语 NMT。通过对比实验,我们证明了在不改变模型的情况下可以提高翻译性能。我们通过实验检查了性能如何随着光束大小变化和 n-gram 阻塞而变化,以及在应用长度惩罚时性能是否得到增强。结果表明,各种解码策略提高了性能,并与以前的韩语-英语 NMT 方法相比较。所以,所提出的方法可以在不使用 PFA 的情况下提高 NMT 模型的性能;这为提高机器翻译性能提供了新的视角。
7.2021-Context-Aware Neural Machine Translation for Korean Honorific Expressions
摘要
神经机器翻译(NMT)是文本生成任务之一,随着深度神经网络的兴起,它已经取得了显著的改善。然而,特定的语言问题诸如处理敬语的翻译问题很少受到关注。在本文中,我们提出了一种语境感知的NMT来促进韩语敬语的翻译改进。通过利用周围句子中说话人之间的关系等信息,我们提出的模型有效地管理了敬语的使用。具体来说,我们利用了一种新的编码器架构,可以表示给定输入句子的语境信息。此外。语境感知的后期编辑(CAPE)技术被用来完善一组不一致的句子级别的尊敬语的翻译。为了证明所提出的方法的有效性,需要有敬语标记的测试数据。
数据是必需的。因此,我们还设计了一个启发式方法,给韩语句子贴上标签,以区分语体和非语体。实验结果表明,我们提出的方法在句子层面的NMT基线上都优于句子级NMT基线在整体翻译质量和敬语翻译方面都优于我们。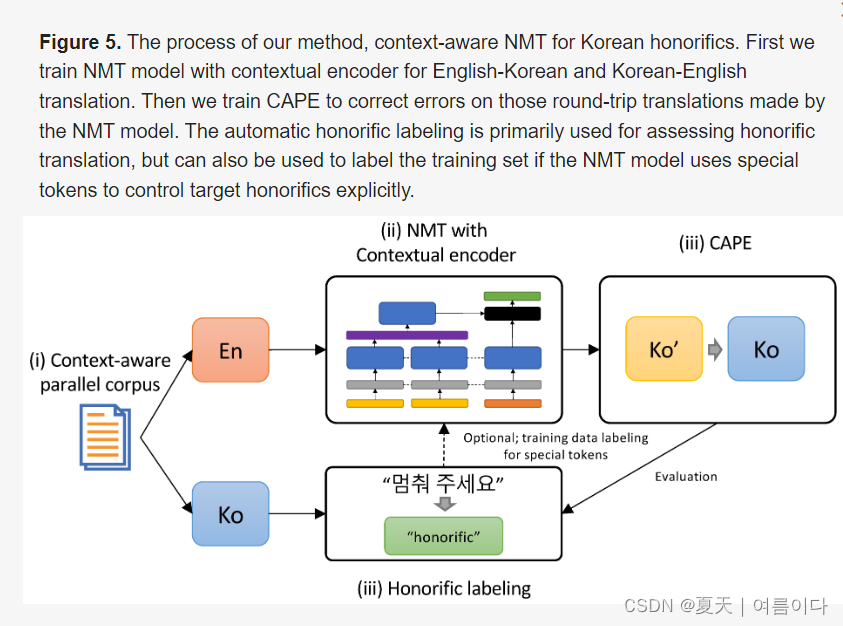
参考文献:
【2】 https://arxiv.org/abs/1409.0473
【3】https://arxiv.org/pdf/1911.11008v1.pdf
【4】 https://arxiv.org/pdf/2008.07772v2.pdf
【5】 https://jeonghyeokpark.netlify.app/assets/2020ialp.pdf
【6】Electronics | Free Full-Text | Decoding Strategies for Improving Low-Resource Machine Translation | HTML 【7】Electronics | Free Full-Text | Context-Aware Neural Machine Translation for Korean Honorific Expressions

更多推荐


 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)