
模型优化之知识蒸馏技术简介
Adlik模型优化器后续将把蒸馏融入模型优化,用更小的模型,提供更高的性能。
1、模型优化背景
最近深度学习算法在计算机视觉上取得了很大成就,由于有了GPU的支持,为了更好的性能,CNN模型可以设计的大而复杂。这就对运行模型的设备有了更高的要求。在资源受限的设备(如手机或者IoT设备)上应用CNN模型,限制主要体现在3方面:1. 模型大小 2.运行时内存 3.计算次数。
举个例子,一个VGG-16模型,需要 138 million参数,占用500MB的存储空间。用这个模型预测一张224*224的图片,需要16 billion FLOPs,93MB额外的运行时内存用于存储中间的结果。因此,大家开始研究模型的优化算法。
模型优化是一个广阔的领域,可以通过量化、快速卷积、低秩分解、剪枝、知识蒸馏等方法实现。知识蒸馏就是模型优化的一个DarkKnowledge[1]。
为什么不直接训练一个小模型,而要采取各种手段进行模型优化呢?
首先,这和遇到问题处理的过程有关。对神经网络来说,有一个共识:模型越大,层数越深,学习能力越强。对CNN,为了完成对数据特征的提取,它往往是过参的。当面对一个任务时,我们并不知道多大的模型是合适的,这时通常会选用一个大模型进行训练,然后再根据训练情况进行调整。如果一开始模型过小,容易欠拟合,不能完成对数据的特征提取。
其次,任何现有的模型不管是VGG16、ResNet50还是近年来的精简模型MobileNet V1/V2,都是精心设计出来的。不是任意的小模型,经过训练,都能达到理想的精度要求。小模型在训练过程中,会碰到欠拟合、训练不收敛、精度低,结果震荡等各种问题。
在剪枝的时候,也不是随意剪枝,就可以完成模型的精简。提出剪枝时,是否对原有模型进行训练并不重要,重要的是在原有模型基础上搜索出一个适合的结构。
正是因为找出适合的模型困难,在深度学习领域,模型设计才会发展为其研究的一个方向,目的是从模型结构出发,设计出一个参数精简,精度足够高的模型;在处理现实问题时,我们很难去设计一个模型,这样模型优化就成为了另一个方向,目的是在训练完成后,解决部署侧的问题。
2、什么是知识蒸馏
知识蒸馏是把大模型(teacher网络)的知识迁移到小模型(student网络)的过程,在蒸馏的过程中,小模型学习到了大模型的泛化能力,保留了接近于大模型的性能。这个大模型可以是单个模型,也可以是多个模型的集成。
蒸馏的做法一般是先训练一个大模型(teacher网络),然后对大模型进行升温,使用这个大模型的输出作为soft target,用数据的真实标签作为hard target,两者联合起来去训练小模型(student网络)。
2.1 为什么会提出蒸馏
大规模的机器学习通常分为2个阶段:训练阶段和部署阶段。
在训练阶段,为了从大量、冗余的数据集中提取特征,通常需要耗费很多计算资源,且对实时性没有要求。最简单有效的提高性能的方法是集成学习,即并行训练多个模型,然后利用多个模型去提取数据特征。
在部署的时候,如果把一个或多个大模型部署到设备中,是相当耗费计算和内存资源的。知识蒸馏提供了一种训练手段,可以把一个或多个大模型的知识迁移到一个小模型上,便于模型部署,加快推理速度。蒸馏能够让小模型很快的学习到大模型的泛化能力,即知识。所谓知识,是一种非常抽象的概念,可以认为知识是输入向量到输出向量的一种映射。
大模型的有价值的知识,也就是这种泛化能力存在于哪里呢?对于普通的分类任务,一般都会将输出类概率最大的那个作为输出,但是错误答案也是有概率的,只不过概率值相对正确的概率较小。这些错误概率的值会有所不同,有的相对大些,有的相对小些。大模型的泛化能力往往就存在于错误答案的相对概率中。比如一张图片如果是猫,模型有很低的概率把它错判为狗,但是几乎不可能把它错判为一辆汽车。这种泛化能力一般需要大模型在庞大的数据集上进行大量训练才能够获得。
如何将这种知识迁移到小模型上去呢?很自然的,我们希望通过训练,使得一个小模型具有大模型相同的泛化能力。普通的分类任务,是把输出和标签(hard target)的交叉熵作为目标函数,希望两者越接近越好。在训练小模型让它学习大模型的泛化能力时,把小模型的输出和大模型的输出(soft target)的交叉熵作为目标函数。soft target的特点是具有高熵值,这需要对网络的logits进行升温才能得到。从大网络学习泛化能力的过程就好比通过加热蒸馏提取有效物质,Hinton形象的把这个训练过程叫做蒸馏。
神经网络通常用softmax作为输出层得到分类的概率,:
![]()
公式中,zi表示网络输出的logits,T是温度参数,通常设为1。T使用更高的温度参数,可以产生软化后的概率分布(soft target)。把T设为更高的参数,比如10,这个动作叫做升温。
下面举一个简单的多分类的例子,说明为什么要对概率分布进行升温软化。比如有很多图片,要通过模型把它们分成4类:牛、狗,猫、车。如果输入的图片是一只狗,这张图片的label的one-hot编码如下:

将这张图片输入神经网络,输出logits:

通过普通softmax输出的概率如下图,可通过公式(1)计算出,此时T=1:

这里可以发现,狗有0.02的概率像猫,有4e-5的概率像牛,最不可能的是车。能够表示数据相似性的信息就存在于错误答案的相对概率中,但是4e-5,2e-9太接近0了,对交叉熵代价函数影响太小,小到可以忽略。为了保留这些有用的信息,提出通过升高温度软化输出的手段,保留这些有用的信息。下图是T=10软化后的概率输出。从下图可见,软化后的输出比普通的概率能提供更多的信息。按照概率值的大小,可以说这张图是一只狗,有可能会被误认为猫,还有可能被误认为牛,这个概率比误认为猫的概率要小,最不可能被误认为车。

2.2 蒸馏过程
蒸馏的过程如下图:
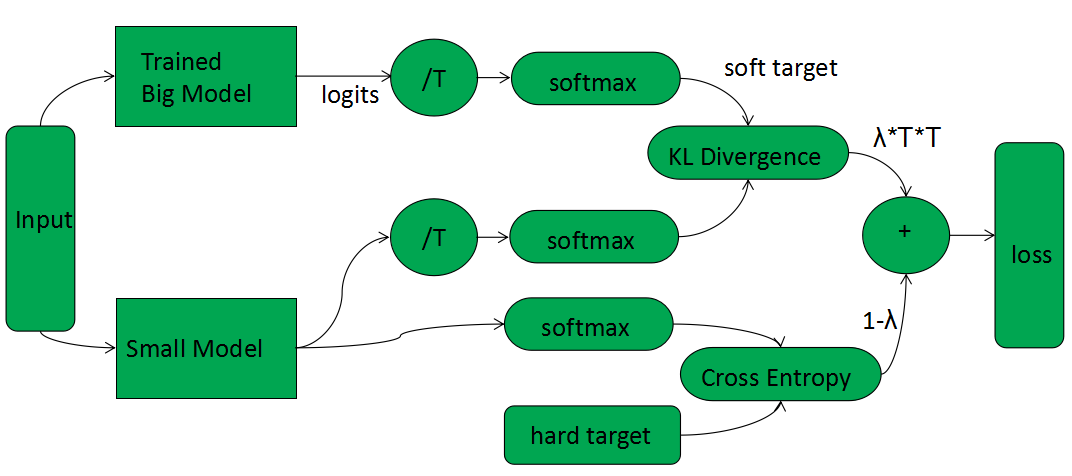
-
用正常的label,即hard target训练出大模型 -
使用训练数据集或迁移数据集进行蒸馏。数据集输入已训练好的大模型,大模型只参与前向传递,输出logits经升温(/T)后,经过softmax,得到软化后的soft target -
同样的数据集输入到小模型,输出logits升高和大模型相同的温度(/T)后,经过softmax,与soft target进行KL 散度计算,得到distillation loss -
同样的数据集输入到小模型,输出logits,经过softmax,与hard target进行交叉熵计算,得到student loss -
训练的总损失函数是distillation loss和student loss的加权求和,公式如下 loss = (2) 公式中,表示distillation loss和student loss相加的权重。一般来说,distillation loss占的权重较大,student loss占的权重较小,这样才会得到较好的蒸馏效果。distillation loss代表着student网络要尽量向teacher网络学习其泛化能力;student loss代表student网络也需要学习生成正确的标签。也就是说student网络既要学习老师的泛化能力,也要针对hard target,对teacher网络进行纠错调整。公式中,T表示温度参数,和公式(1)中的含义一致。distillation loss需要乘以,是因为在对soft target的损失函数进行梯度计算的过程中,幅度会缩小,而对hard target的损失函数进行梯度计算时,不会有这个因子产生,为了平衡distillation loss和student loss对loss的贡献基本不变,需要对distillation loss做乘以的操作。 -
将蒸馏训练出的小模型部署到环境中,用于推理。在推理时,注意T需要设为1。
2.3 蒸馏技术的应用
蒸馏可以是一个大模型向小模型进行蒸馏,也可以是多个大模型的集成向小模型进行蒸馏。在笔者对mnist数据集进行蒸馏的实验中,teacher模型选用卷积网络,student模型选用小型的全连接网络,teacher模型和student模型的结构如下:
>Model: "teacher"
>\_________________________________________________________________
>Layer (type) Output Shape Param #
>\=================================================================
>conv2d (Conv2D) (None, 26, 26, 32) 320
>\_________________________________________________________________
>conv2d_1 (Conv2D) (None, 24, 24, 64) 18496
>\_________________________________________________________________
>max_pooling2d (MaxPooling2D) (None, 12, 12, 64) 0
>\_________________________________________________________________
>dropout (Dropout) (None, 12, 12, 64) 0
>\_________________________________________________________________
>flatten (Flatten) (None, 9216) 0
>\_________________________________________________________________
>dense (Dense) (None, 128) 1179776
>\_________________________________________________________________
>dropout_1 (Dropout) (None, 128) 0
>\_________________________________________________________________
>dense_1 (Dense) (None, 10) 1290
>\=================================================================
>Total params: 1,199,882
>Trainable params: 1,199,882
>Non-trainable params: 0
>\_________________________________________________________________
>Model: "student"
>\_________________________________________________________________
>Layer (type) Output Shape Param #
>\=================================================================
>flatten_1 (Flatten) (None, 784) 0
>\_________________________________________________________________
>dense_2 (Dense) (None, 32) 25120
>\_________________________________________________________________
>dense_3 (Dense) (None, 32) 1056
>\_________________________________________________________________
>dense_4 (Dense) (None, 10) 330
>\=================================================================
>Total params: 26,506
>Trainable params: 26,506
>Non-trainable params: 0
>\_________________________________________________________________
>从网络结构可以看出老师网络有1199882个参数,学生网络有26506个参数,老师网络的参数量是学生网络的45倍。经过训练,老师网络的精度大概是98.9%,如果不蒸馏,单独训练学生网络的精度是95.6%;通过蒸馏学生网络的精度是96.6%。在实验中,T=2,,,,其中表示teacher网络的学习率,表示单独训练student网络的学习率,,表示蒸馏时学生网络的学习率。
通过实验,小模型的参数量只有大模型的2%,但是精度只下降了2.2%。通过蒸馏提高了小网络大约1%性能,增强了小网络的稳定性。在蒸馏过程中,都是需要调整的超参,只有找到合适的超参,才能蒸馏出较好的小网络,这也是为了提升小网络的性能需要付出的代价。
蒸馏技术作为一种模型优化技术,应用领域广泛:可以用于图像分类任务,可以用于BERT之类的预训练语言模型,也可以用于目标检测。它是模型优化的一个方向,可以与剪枝、量化等方法一起使用,实现模型压缩加速。
Adlik模型优化器后续将把蒸馏融入模型优化,用更小的模型,提供更高的性能。
参考资料
[1]http://www.ttic.edu/dl/dark14.pdf [2]Geoffrey E. Hinton, Oriol Vinyals, and Jeffrey Dean. Distilling the knowledge in a neural network. arXiv, abs/1503.02531, 2015. [3]Victor SANH, Lysandre DEBUT, Julien CHAUMOND, Thomas WOLF. DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter. arXiv:1910.01108, 2019. [4]https://keras.io/examples/vision/knowledge_distillation/#train-student-from-scratch-for-comparison [5]Zhuang Liu, Mingjie Sun, Tinghui Zhou, Gao Huang, Trevor Darrell. Rethinking the value of network pruning. arXiv preprint arXiv:1810.05270, 2018.

更多推荐


 0
0 0
0- 0



 已为社区贡献77条内容
已为社区贡献77条内容

所有评论(0)