
模型优化算法——AutoSlim
AutoSlim是一种one-shot模型优化方法,只要给定网络类型(如MobileNet-v1,ResNet50),给定限制条件(如Flops、latency等),就能自动决定每一层的通道数。
1、概述
AutoSlim是一种one-shot模型优化方法,只要给定网络类型(如MobileNet-v1,ResNet50),给定限制条件(如Flops、latency等),就能自动决定每一层的通道数,以达到最优的模型精度。该优化方法打破了人工设计模型的“half size, double channel”的假设,解决了需要人为评估模型每一层敏感度,人为设置剪枝层/剪枝层类型的痛点,降低了使用剪枝技术的门槛和学习成本。
AutoSlim的算法流程图如下:
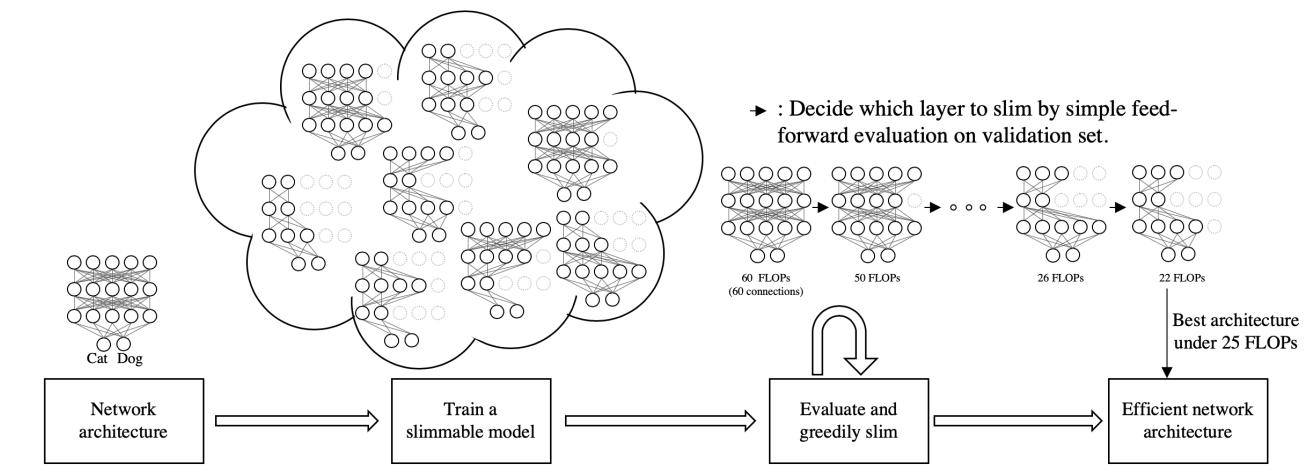
-
需要给出一个网络结构 -
训练一个slimmable model作为supernet,这里的slimmable model是指nonuniform universally slimmable networks,即所有层的通道不是通过一个统一的width ratio来进行调节。训练的epochs数大约为常规训练的20%-50%。 -
在验证集上,采用贪婪的方式,使用已训练好的supernet进行前向推理,迭代评估,最后找到满足限制条件,同时精度降低最小的网络,这个网络成为子网。更具体的说,greedily slim是指在一次迭代中,将每一层的通道进行分组,每一组是一个channel bin,尝试剪去每一层的最后一个channel bin,查看前向推理精度,精度最高的那层剪去最后一个channel bin,如此循环,直到满足限制条件。通过分组的方式可以减小搜索空间。 -
重新训练一个或多个子网。
该算法基于一个假设:作为supernet的slimmable model可以作为已知通道配置的独立训练的网络的精度评估器。
2、slimmable networks原理
AutoSlim在slimmable networks的基础上发展起来,具体见[1][2]。下面我们先简单介绍一下slimmable networks和universally slimmable networks。
2.1 slimmable networks
最初的slimmable networks使用switchable BN进行训练,不同的子网使用不同的BN,在训练完成后,supernet只能支持指定的多个width ratio。这种slimmable networks称为S-Net。S-Net的训练目标是所有switch下,模型精度平均是最优的。slimmable networks的训练算法如下:

说明:在调用loss.backward()时,梯度如果不清零,会反向传播,并进行累加,调用optimizer.step(),会根据累加的梯度更新网络参数。optimizer.zero grad()负责对梯度清零。
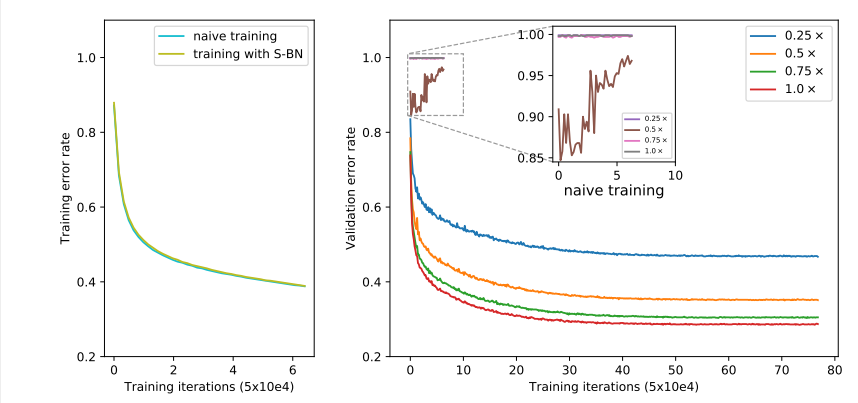
之所以使用switchable BN,主要为解决不同子网结构时,共享BN带来的统计信息的不一致的问题。在训练的时候是没有问题的,因为使用的是当前batch的均值,方差。但是在推理时,如果不使用switchable BN,不同的子网结构统计的均值,方差的不同,如果共享BN,统计出来的均值方差是不准确的。switchable BN本质是不同switch的网络私有化BN。下图是训练和推理slimmable networks的曲线。左侧是switch切换到最大时的训练误差。右侧是在不同的switch下验证集下的测试误差。可以看出来,不管是普通的训练方式还是使用switchable BN的训练方式,训练误差是一致的(左图),但是如果不使用switchable BN,测试误差会很高(右图,放大的区域,naive training)。如果使用switchable BN训练slimmable networks,那不管是训练还是测试误差,都能保持稳定。
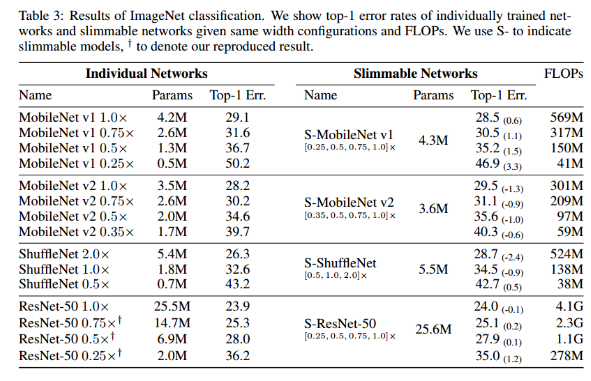
下表是slimmable networks用在MobileNet v1,MobileNet v2, ShuffleNet,ResNet-50,在ImageNet数据集上的测试结果,表中,S-表示slimmable models。可以发现slimmable networks能够提供和独立训练的网络相当的性能。值得注意的是,slimmable networks在一些情况下还会改善网络的性能。比如S-MobileNet v1在1.0×时,比独立训练的网络精度提高0.6%,S-MobileNet v1在0.25×时比独立训练的网络精度提高3.3%,作者猜测这样显著的性能提升是因为训练slimmable networks时的联合训练和权重共享,其间隐含着大模型向小模型的知识迁移,即隐含着一个知识蒸馏的过程。
2.2 universally slimmable networks
由于S-Net只能在训练时指定的若干个switch之间切换,为了解决这个问题,后续又提出了universally slimmable networks ,可以在指定的width范围内的任意width之间进行切换,简称 US-Net。主要的改进有3点:
-
训练supernet时使用普通的BN,进行BN共享,在训练完成后,使用训练数据集(对ImageNet,随机采样1000图片即可)进行BN校准:此时模型处于eval模式,BN处于train模式。 -
使用三明治法则(sandwich rule)解决了高效训练US-Net的问题。训练US-Net一个自然的方式是在每个迭代中累加或平均多个subnet的loss。采样的子网越多,训练出的网络性能应该越好。但是这样会消耗巨大的计算资源。三明治法则指明了子网采样的最优方式,在网络性能和计算资源之前取得一个平衡,具体说来,三明治法则是指在训练的每个迭代中,训练n个subnet,其中一个是最小宽度,一个最大宽度,还有(n-2)个随机宽度。n一般取4。 -
使用原地蒸馏(inplace distillation)提升了US-Net的整体训练精度。原地蒸馏是指用最大宽度的模型的输出和数据集的label取交叉熵作为loss进行反向传播,然后最大宽度的模型作为其他宽度模型的老师,用其输出作为soft label和其他宽度的输出分别取交叉熵进行反向传播,这样的蒸馏就叫原地蒸馏。
训练US-Net的算法如下:

下图是US-MobileNet v2与I-Net,S-Net的性能对比。可以看出,平均来看,US-net的性能优于S-net,和I-net(独立训练的网络,网络通过width-ratio调整大小)。

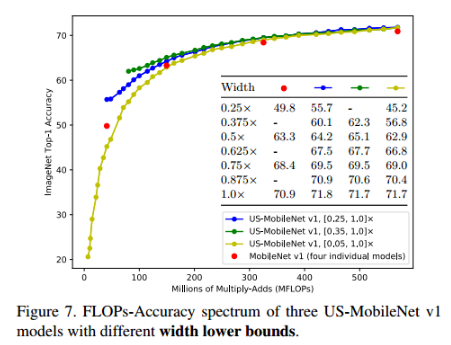
下图是三明治法则取不同下边界的扩展实验。可以看出,宽度的下边界非常重要。US-Net的性能是构建于下边界的基础上。
2.3 nonuniform US-Net
US-Net中, width ratio用于一个模型的所有层。nonuniform US-Net是指模型中,每一层的width ratio是独立的,不需要像US-Net一样,所有层用同一个ratio,这样每一层裁剪后,需要相同通道数的层就会出现通道数不一致的问题。这是nonuniform US-Net需要解决的问题。Autoslim中使用的正是nonuniform US-Net。
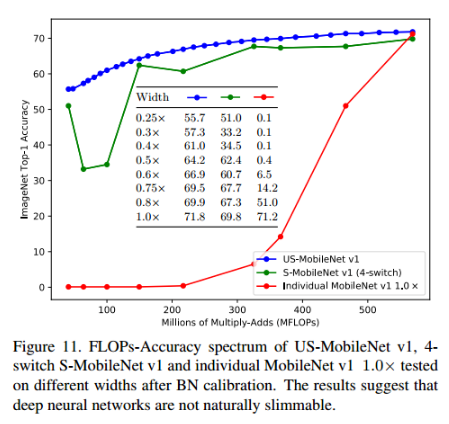
2.4 深度学习网络是天生就可以进行network slimming吗
看下图,就知道答案是否定的。一个独立训练好的深度学习网络I-Net(即没有用slimming network的方法训练supernet的网络),即使进行了BN校准,它在不同width下的推理精度也是很差的。slimming network之所以有效,除了对BN进行处理,还有就是权重的共享和联合训练,这点至关重要。
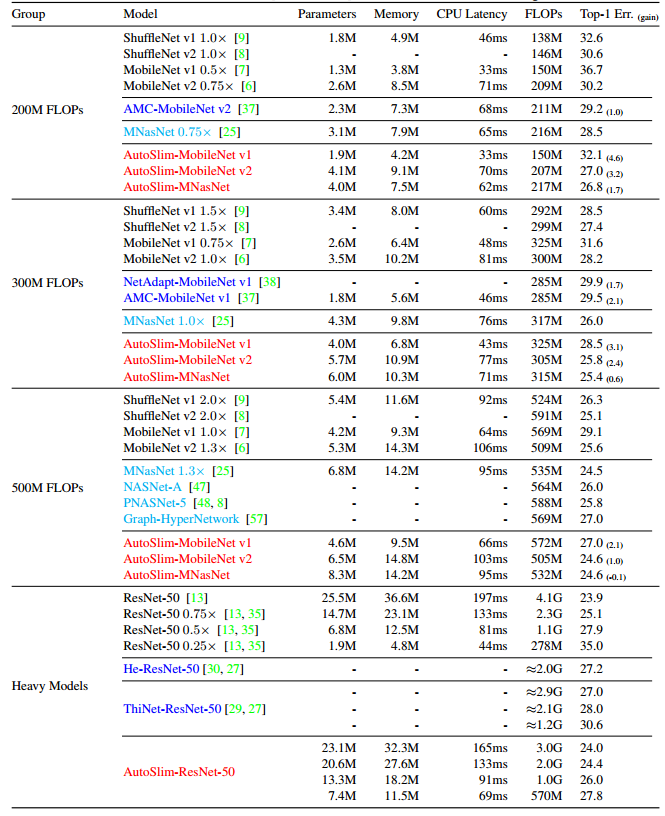
3、AutoSlim在ImageNet上的效果
AutoSlim在ImageNet上的效果见下表。论文作者分别对FLOPs为200M、300M、500M的网络和重型模型(基本上是基于ResNet-50的模型)进行了测试。从一系列的实验结果可见,在相同的FLOPs下,AutoSlim搜索出的网络在精度上和I-Net相当或更高,不少网络在latency上更具优势。
好了,有关AutoSlim的介绍就到这里了。

更多推荐


 0
0 0
0- 0



 已为社区贡献77条内容
已为社区贡献77条内容

所有评论(0)