
面向ASIC设备的编译器框架:TVM or MLIR?
目前TVM和MLIR都没有完全支持定制DSA的设计、上层编译的成熟路线,也就是最终选型的结果对实际工程开发的影响不会很大,都需要开发者/团队深度定制大量代码。
2019~2021年,“摩尔定律失效”这一关键词频频出现于各大技术网站,在此背景下,市面上多如牛毛的AI芯片公司不约而同地给出了通用CPU+专用ASIC芯片的方案,以应对日益增长的AI边、端侧推理计算需求。在AI DSA芯片的开发实践中,棘手的问题除了底层硬件的设计,更多的还是AI模型在DSA芯片上优化、部署执行这一过程所需软件栈的实现,也即“AI编译器”技术栈,在这一领域最常常被大家提起并衡短论长的,莫过于TVM和MLIR。
严格来说,MLIR和TVM并不适合在一起对比:TVM是面向深度学习的模型编译器,用户可借此可直接获得编译/优化模型为推理blob的能力(可以看做机器学习时代的GCC、Clang),有兴趣了解TVM的同学可以参考这里;MLIR则是编译器基础设施类软件(可以看做机器学习时代的LLVM),面向的是需要构建自定义编译器的用户,它的基本设想是通过MLIR的Dialect共享生态减少用户开发编译器的工作量。
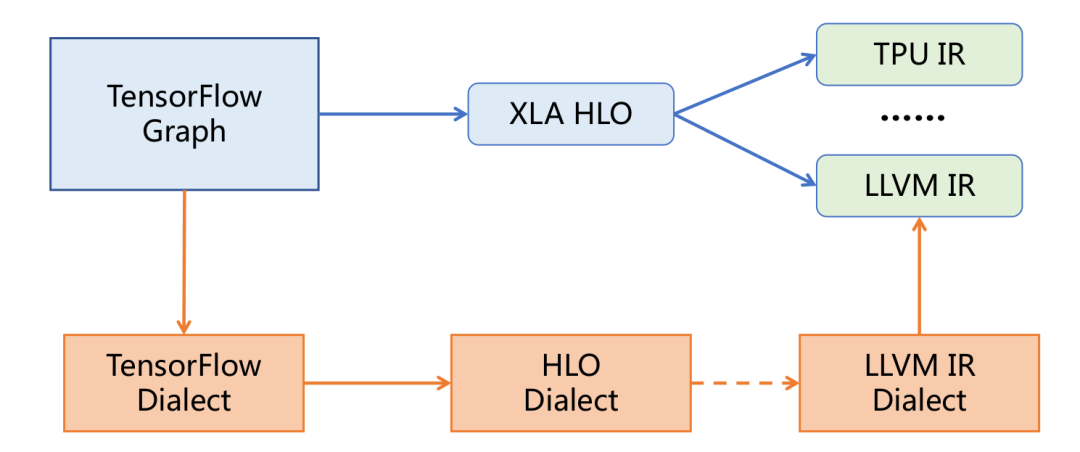
以上图为例,TensorFlow本身的优化推理过程如蓝色和绿色部分所示:TensorFlow Graph首先转换为XLA的HLO IR,应用XLA的优化Pass后再lower到目标设备的IR,例如对于x86/arm可lower为LLVM IR等,这样做的问题在于:
-
XLA的图优化Pass是封闭的,用户如果想在其他框架例如TVM下实现同样的优化,需要阅读XLA的源码和TVM的源码,并添加Pass代码到TVM中,开发成本很高
-
XLA HLO到LLVM IR的跨度太大,实现开销大,此处的开销包括各类针对微架构的带宽、缓存、指令集的优化
MLIR解决问题的方式如上图红色部分所示:先把外部IR转化为MLIR格式的Dialect IR(Translation),再把该IR lower到其他的MLIR方言IR(Conversion),最后从Target Dialect IR转出为Target IR(Anti-Translation),这么做的好处是,如果lower过程中所需的IR Dialect以及Target Dialect已经由MLIR生态中的其他用户实现了,那么你就可以直接从这些Dialect及其对应的优化Pass中受益。假设方言Memory擅长做内存分配优化,那就convert过去执行优化;假设Tile方言做Conv Tiling优化很好,那就从Memory IR convert过去继续优化...
MLIR的设想虽然非常好,但具体实现方面MLIR框架并没有直接解决上面列出的问题,而是把问题摊派给了加入MLIR生态的用户们:
-
TensorFlow/Onnx/Torch等IR转为MLIR的Translation工作(入口工程),需要各框架团队以及开源社区支持 -
Dialect之间并不天生支持完美切换,用户有需要时需要自行定制开发,然后根据个人意愿开源 -
Translation工程、Conversion工程都有可能因为上游IR版本变动引入新bug,也就是上游项目变动需要几何级数的下游项目联动
-
总之,MLIR的设想虽然很棒,但在其生态完全爆发前,其工程开发总量也会很惊人。
支持上层模型,谁更完备?
TVM:TVM通过其relay.frontend模块下的功能实现高层模型转为TVM Relay IR,目前TVM支持MXNet、Keras、Onnx、TFLite、CoreML、Caffe2、Tensorflow、Darknet、Pytorch、Caffe和Paddle模型的输入,转换后的Relay IR可以被配套的图优化Pass进一步优化。
MLIR:目前已知部分主流框架实现了Dialect入口项目以加入MLIR生态:Onnx-MLIR、Torch-MLIR、Tensorflow-MLIR,这些项目通过自定义Dialect将Framework IR转换为MLIR格式的IR(Translation),转换后的IR可以通过Convert到其他Dialect的方法逐步lower到目标IR(Conversion)的MLIR方言,再通过反向的格式翻译为Target IR,如LLVM IR,进而生成可执行文件。
-
对于上层主流框架TVM的支持更全面,且配套了常用的图优化Pass集合;MLIR相比起来支持框架没有那么全面,转换后的图优化Pass数量取决于对应Dialect内置的Pass数量。
适配底层硬件,谁更方便?
适配底层硬件通常有两方面考量:对底层硬件设计过程的支持;模型编译优化过程的支持。
-
支持硬件设计:传统硬件架构设计和上层编译器设计通常是“两头凑”模式,即硬件设计专注于在当前制程下优化架构,编译器则专注于基于架构设计IR的优化、编译过程;但在AI芯片领域,计算需求的变更周期更短,我们更希望两者协同性更好以适应快速的需求迭代,理想情况下给出DSA计算核心描述,即可立即获得硬件的RTL级描述代码。 -
支持编译优化:即从模型图IR到芯片可执行代码的编译器软件栈。
TVM目前开源的面向底层硬件的开发模块是VTA,全称为Versatile Tensor Accelerator,直译为灵活的张量加速器,下图是VTA在TVM框架整体技术栈中的位置:
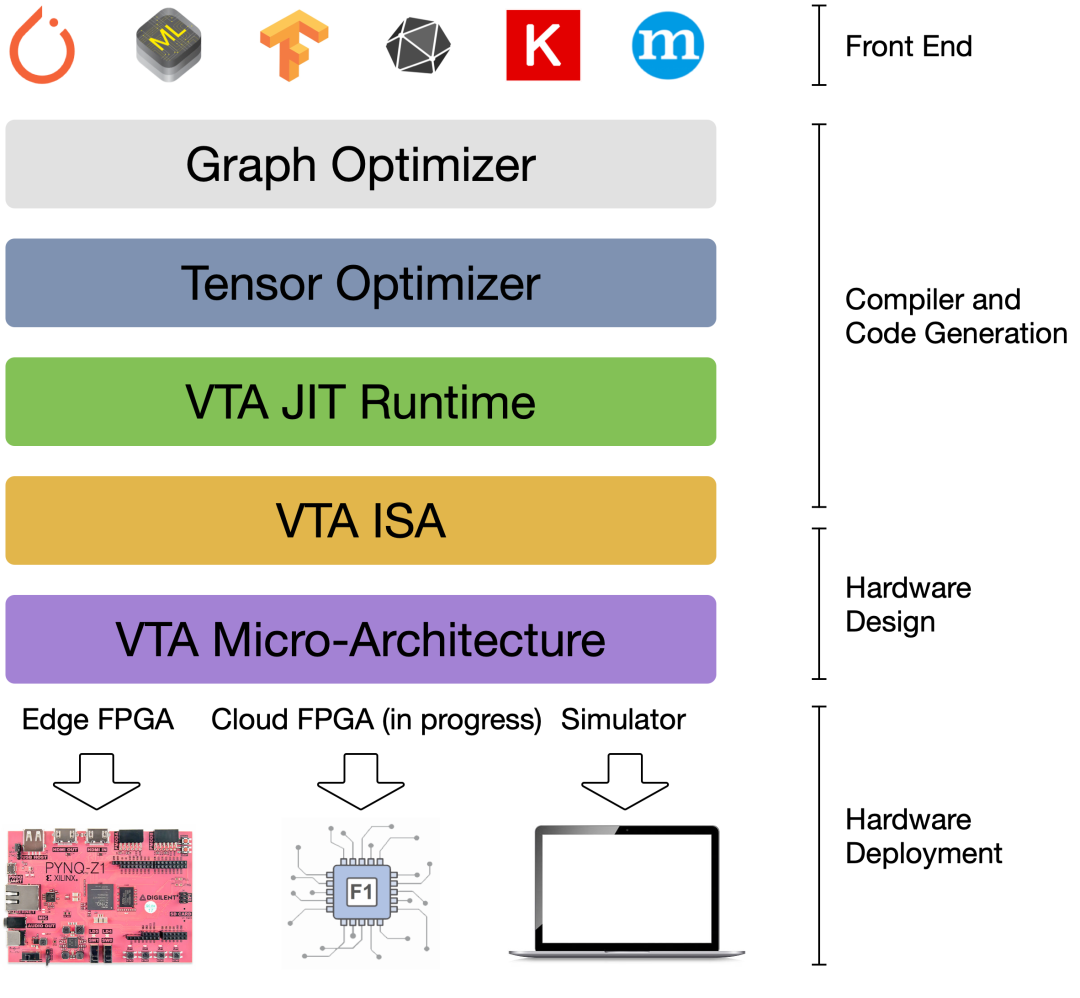
从下向上看,基于FPGA的arch设计需要遵照VTA的微架构(取指、读、存、算),该架构下要实现VTA的ISA(读、存、GEMM、ALU),满足微架构和ISA要求的硬件即可运行VTA Runtime,支持算子执行;从上向下看,运行VTA运行时的ASIC,默认支持TVM技术栈的所有优化手段,包括图优化、算子优化以及AutoTune等编译优化和代码生成技术。VTA的微架构如下所示:
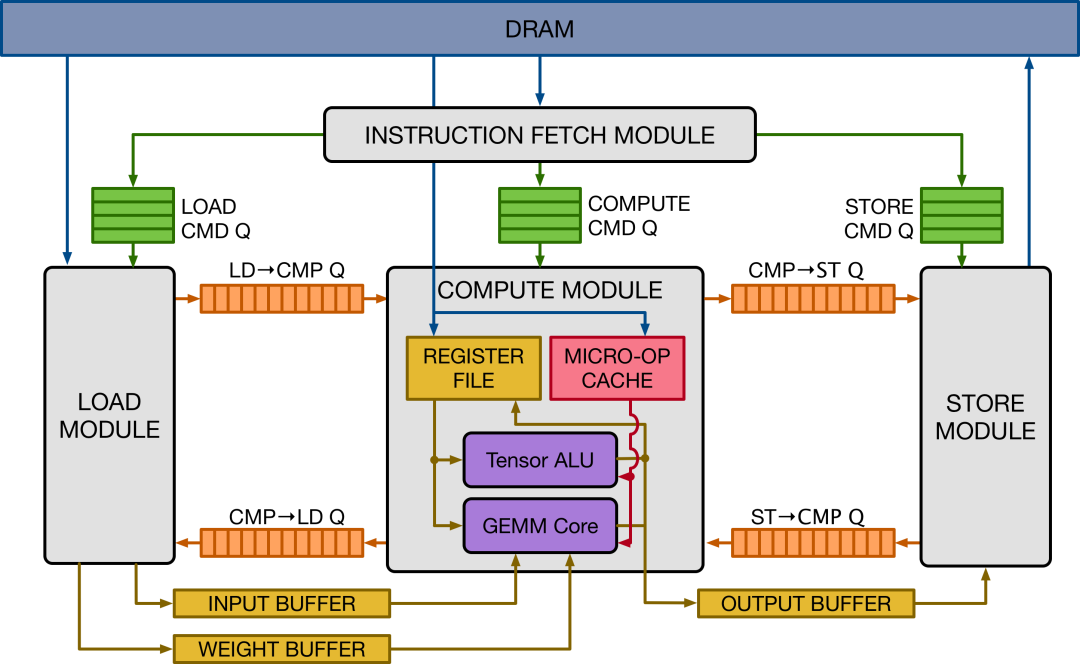
VTA的微架构包括四个必须实现的模块:Fetch模块负责从DRAM取指到其余三个模块配套的FIFO队列;LOAD模块根据当前指令从DRAM中读取数据;STORE模块和LOAD模块功能相反;Compute模块除了包括模块内部的寄存器文件和RISC OP缓存,还包含核心的两种计算单元——ALU和GEMM核心。
VTA的ISA是一种类CISC的规范,包含4个CISC指令:LOAD/STORE/GEMM/ALU,LOAD负责从DRAM中读取2D Tensor到输入buffer、权重buffer或寄存器文件中,或者读取micro-kernel到micro-op 缓存,此外还需支持输入/权重buffer的动态padding;Store指令负责将输出的2D Tensor写回DRAM;ALU会被分解为一个micro-op序列,在矩阵Tensor上执行Elementwise类计算;GEMM会被分解为一个micro-op序列,负责矩阵乘计算。
一些限制:VTA主推的硬件开发代码并非目前EDA领域主流的Verilog/SystemVerilog实现的RTL描述代码,而是Xilinx的HLS C++代码;ISA虽然支持一定级别的扩展,但ISA指令目前只可处理二维Tensor是很硬的限制。
-
小结:VTA配合TVM提供了一整套针对开源深度学习的专用硬件开发的硬件设计、编译器和上层优化软件的全栈工具链,虽然设计硬件时会受限于其ISA和MicroArch,但它的确降低了机器学习从业者开发DSA芯片的门槛。
MLIR对底层硬件设计的支持方面,最近活跃度比较高的项目是Clang创始人Chris Lattner发起的开源项目CIRCT,其全称是Circuit IR Compiler and Tools,即基于电路中间表示的编译器和设计工具,该项目将DSL/IR/Compile等软件开发的思想应用到开源硬件设计领域,以加速硬件设计的流程,同时也寻求解决EDA工具的零碎化及封闭化的缺陷。
下面的图是Chris在ASPLOS 2021大会用的一张slide,蓝色的框为通用处理器(CPU/GPU/TPU),灰色的为专用处理器,可以看出CIRCT的希望是配合现有的MLIR生态覆盖通用+专用处理器场景,统一这些场景下开发所需的零碎工具到一个统一的EDA框架下:基于MLIR的软件框架可以涵盖软件开发工具(红线左),而CIRCT覆盖硬件设计工具(红线右)。
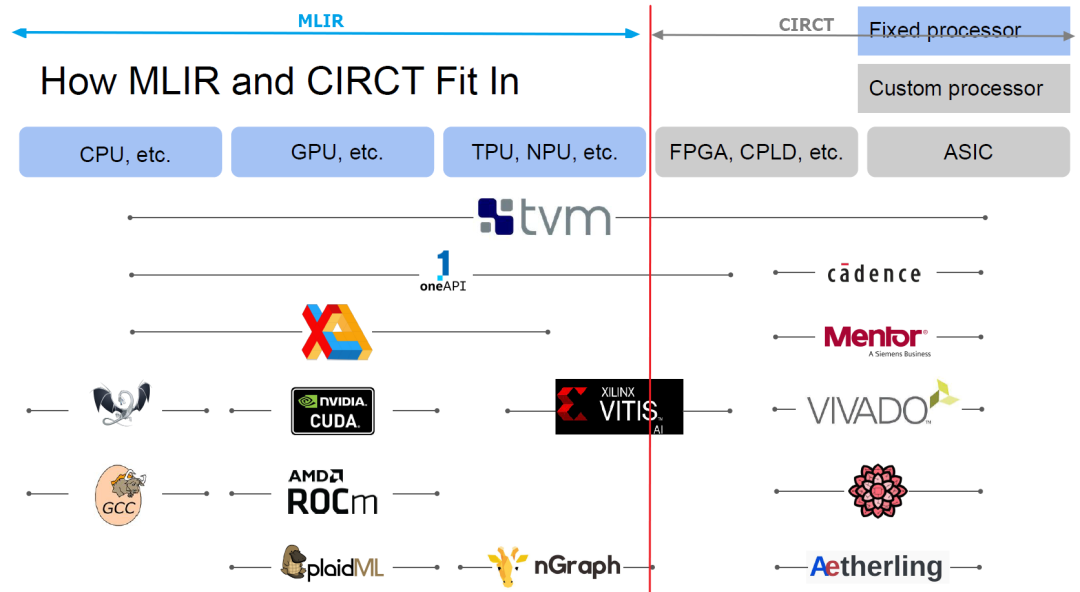
CIRCT的软件栈如下图所示,大体上软件站分为两部分:蓝色的是MLIR Core Project里的基础设施,包括Linalg/Affine/Vector/Standard这些核心方言;灰色的是CIRCT整合的硬件开发相关的方言,这些方言目前尚无统一的组织结构,更像是NAS领域的NNI(方言沙拉),例如Handshake由Xilinx研究人员开发,用于描述独立的非同步数据传输,定义了握手模型和fork/join/mux等控制逻辑;HIR是印度理工的研究人员开发的高层次时序电路描述方言,用来表示带延迟的计算、流水线、状态机等;下一层的FIRRTL是Chisel编译器的IR,Seq描述时序电路,Comb描述组合电路;最底层的LLHD是受LLVM启发的针对硬件RTL代码的多层IR表示,计划支持Chisel, MyHDL, SystemVerilog。
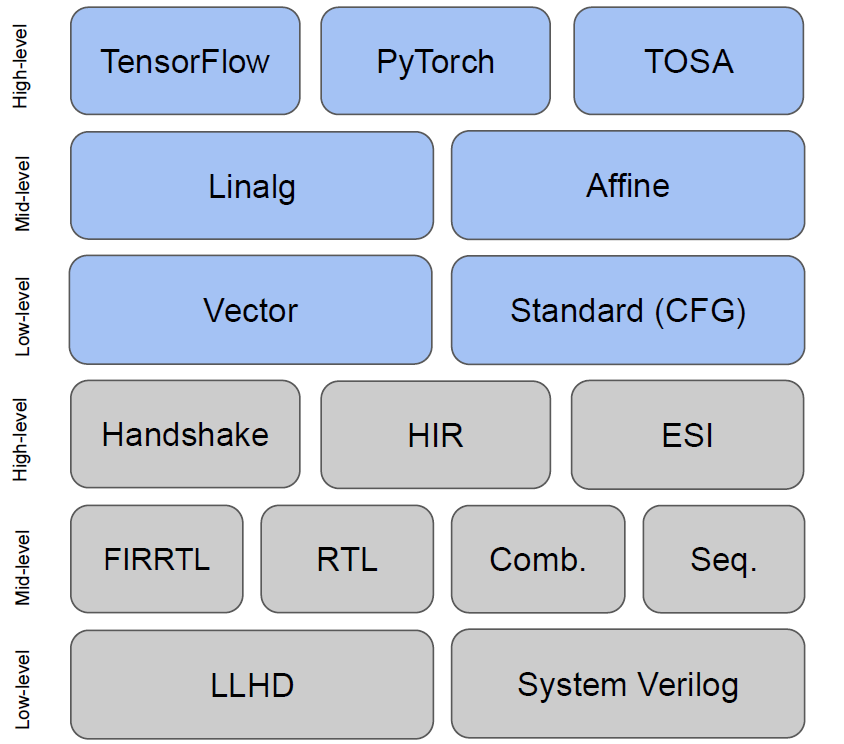
下图是以上方言之间的部分转换关系,可以看出,若我们要将MLIR的Core Dialect转换为Verilog Dialect,可以选择的路线为:
FIR -> high FIRRTL -> mid FIRRTL -> low FIRRTL -> Verilog
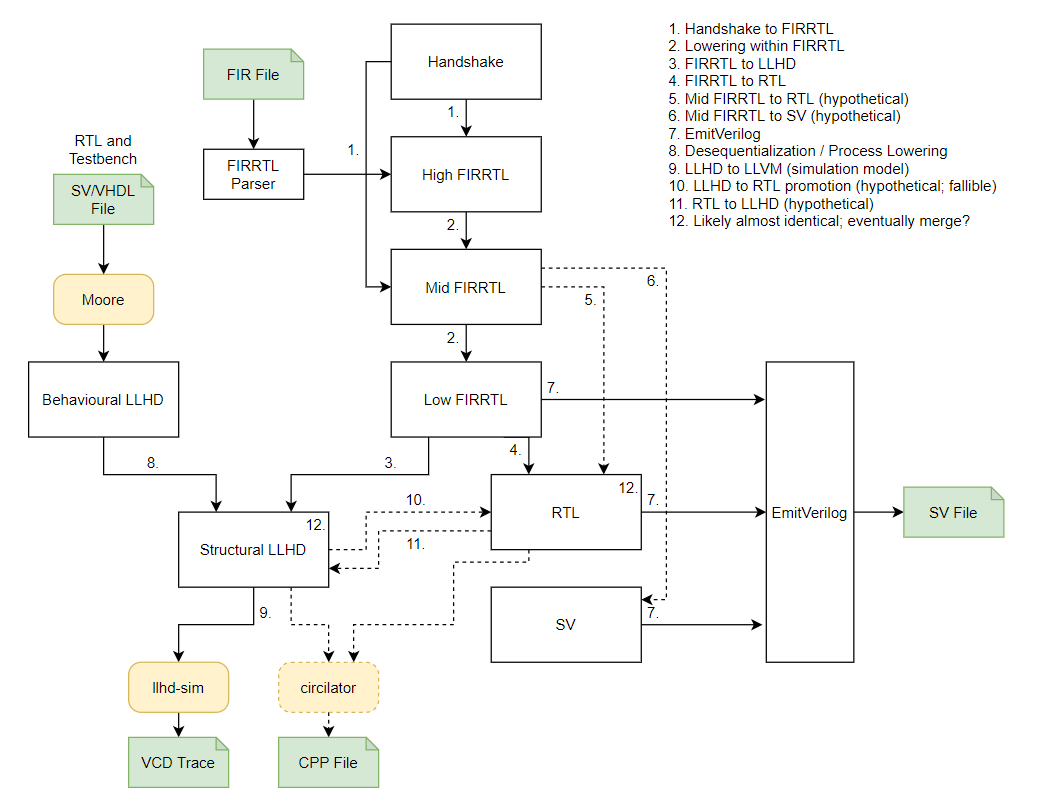
编译器软件栈方面,MLIR生态中针对DSA较常见的做法是先把高层模型的IR转化为MLIR,再经过逐层lower下沉到目标硬件级MLIR,如LLVM Dialect,最终把LLVM Dialect转为LLVM IR,除了以上MLIR内部的“打洞”工作,基于LLVM/GCC支持生成芯片上可执行代码的工作包括:
-
后端指令描述(ISA) -
后端特性支持,包括栈设计、寄存器描述 -
后端优化:指令调度支持、特殊支持生成、硬件loop、条件执行指令 -
特殊后端优化:循环展开、delay slot调度...
-
总结:TVM的VTA在硬件设计、编译器软件栈方面的开发支持很完备,但需要用户设计硬件时遵循其自主设计的ISA,对硬件设计的限制很大;MLIR没有这方面限制,但在DSA的HW/SW协同设计方面以及模型编译支持方面,开源生态中没有成熟的“全栈”方案。
一点看法
回到本篇主题,首先毫无疑问的,TVM-VTA方案在易用性和开发效率的优势应该是没有争议的,其开发流程最容易上手,开发者无论是设计硬件还是在硬件上优化算子实现的开发代价都比基于MLIR开发小很多。但对于实际开发DSA产品的团队,能做到完全不在意其微架构和指令集的限制几乎是不可能的;不考虑VTA的情况下,目前TVM和MLIR都没有完全支持定制DSA的设计、上层编译的成熟路线,也就是最终选型的结果对实际工程开发的影响不会很大,都需要开发者/团队深度定制大量代码。

更多推荐


 0
0 0
0- 0



 已为社区贡献77条内容
已为社区贡献77条内容

所有评论(0)