
ICCV2021 Google Landmark比赛Kaggle金牌方案分享
本着学习和follow最新知识的想法,在业余时间参加了本次比赛并有幸获得该比赛两个赛道的金牌,本文将对该次比赛所使用到的一些技术和算法进行介绍。
摘要
目前图像检索和实例识别技术迅速发展,需要新的数据集和挑战赛来衡量相关算法的性能,Google Landmark competition作为图像检索和细粒度识别领域的标志性比赛迄今为止已经在全球最大的机器学习竞赛平台Kaggle上举办到了第四届,有非常多著名且优秀的算法在该赛中被提出和验证。本着学习和follow最新知识的想法,在业余时间参加了本次比赛并有幸获得该比赛两个赛道的金牌,本文将对该次比赛所使用到的一些技术和算法进行介绍。
1 比赛介绍
1.1 数据集及评价指标
本次比赛提供的数据集1有超过500万张图片,地标种类超过20万种,当然该数据集并不是干净的数据集,其中不属于任何地标的图像占比超过25%,训练集中有4132914张图片,测试集中包含150万张图片。
本次竞赛所使用的评价指标为:全局平均精度(Gap/Golbal average precision)进行评估。对于每个测试图像,如果该图中包含一个地标景点,最终的输出将预测一个地标标签和相应的置信分数。评估将每个预测视为一长串预测中的单个数据点(按置信度得分降序排序),并根据该列表计算平均精度。如果提交文件中有N个预测(标签/置信对)按其置信度得分降序排序,则全局平均精度计算为:
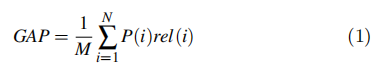
P(i) 是排序i的预测准确度,例如对于i为3的预测结果,代表着其已经输出了3个预测,假设其中两个是正确的,那么P(3)=2/3。
rel(i) 表示排序i的预测相关性:如果第 i 个预测正确则为 1,否则为0。
上述公式可能略微抽象,下面将举一个具体的例子来帮助理解Gap计算方式:假如输入5张图分别返回这5张图的类别以及置信度得分,先将其根据得分进行排序,如下表所示:

最终上述5张图的预测结果给出的Gap值为(1+0+0.66+0+0.6)/5。通俗的来讲就是该指标要求的结果是预测的结果不仅要准确,而且置信度得分要尽可能高于错误的预测结果,置信度高的错误结果会带来巨大的Gap损失,并且由于该数据集有大量的不属于任何类别的非地标图片,如果给出这样的图片高的置信度是很难接受的,因此除了初步的召回与其相似的Topk图片之后,并不能直接将其同最相似的图片的标签对应起来,还需要进一步进行re-rank精排序。
2 方法介绍
2.1 深度学习图像检索基础知识
输入单张图片,图像检索首先使用深度学习backbone进行提取特征映射,该特征映射通过全局聚合层聚合为固定长度的全局特征表示。最后,将该特征映射使用FC层或者CNN层进行投影,并使用L2对其进行归一化,以便可以有效地将该图像特征同其他图像特征进行点积比较,计算该图像同其他图像的相似度,通过向量召回可以筛选出跟该图最相似的K个图片。

Fig.1 深度学习图像检索基本流程图
图像输入网络中,通过各种Metric Learning 的损失函数优化类间和类内距离,下图所使用的是Triplet loss,其作为一种pair-based loss使用成对的样本,通过相同的模型提取特征,最终去优化该特征之间的距离,使得相似样本的特征向量之间距离小,不同样本间距离大,从而对数据进行区分。

Fig.2 深度学习图像检索模型基本训练流程图
2.2 Model Design
在本次比赛中最终方案选取了三个模型Swin transfromer[2]、SE-ResNet-101[3]和NFnet[4]作为基础网络模型。在此之上,方案借鉴了R-MAC[5]中提出的Regional(局部块)的思想对Gem[6]进行了修改,修改后的网络层被我们起名为R-Gem被加入到网络中,Gem中的p参数初始化设置为3并且在训练中通过反向传播不断被修改,实验结果表明其对于细粒度图像的全局特征提取有着显著的提升作用。关于损失函数的选择,我们尝试了多种不同的Metric Learning损失函数例如ArcFace[7], CosFace[8], AdaCos[9],curricularface[10]等,最终选定了腾讯优图实验室在2020CVPR中提出的curricularface损失函数作为该模型的损失函数,其通过自适应的方式极大的增加了模型的收敛效率,对于难样本的动态处理使得其最终结果往往优于其他几种损失函数。在该次实验中,curricularface的两个参数s和m分别被设置为30和0.4。
2.3 Traning Details
在模型的训练过程中,方案使用的训练策略是一步步逐渐增大图像尺寸的方式进行训练,即逐步在448x448,512x512,640x640的尺寸下训练8个epoch,最后在736x736的图像尺寸下fine-tune 4个epoch作为最终的检索模型。关于图像的增强策略,方案使用了HorizontalFlip(水平翻转),ImageCompression(质量压缩),ShiftScaleRotate( 随机应用仿射变换:平移,缩放和旋转),Cutout(添加噪声块)等数据增强的策略来增加模型的鲁棒性和召回准确率。
优化器选择为adamW优化器,scheduler设置为cosine annealing。
3 Re-rank strategy
相较于模型的"常规"化,精排序的方法总是天马行空和多种多样的,同时也是比赛或者真实项目中最为关键的一环,我们在该次比赛中尝试了各种各样不同的精排序方法,接下来的部分将对在该次比赛中尝试过后几种较为有效的重排序策略进行简要的介绍。
首先介绍一下在该赛中精排序所优化的动机:1.首先对于某张图片,首先会召回跟它最相似的Topk张图片(在比赛中K取值为10),由于模型预测错误或者数据集的原因,可能点积最接近的图片的标签并不是正确的预测结果,因此第一个动机即精排序往往能够带来更好的预测结果2.此外本数据集有大量的非地标图像出现,且评价指标为Gap,如果预测的非地标图像(干扰物)的置信度高于地标图像,对于最终得分的降低是不太能够接受的,因此第二个动机即对这些干扰图像的预测可信度得分进行抑制。
3.1 Query Expansion
拓展查询(QE, Query Expansion)是一种相对传统的精排方法,其最早在文本检索领域被提出,后来被用于图像检索领域,具体指的是返回的前Topk个结果,包括查询样本本身,对它们的特征求和取平均,以此为检索特征,再做一次查询,无数实践证明,拓展查询是一种易于实现且能够有效的提高召回率的一种重排序方法。
3.2 Soft-voting
Soft-voting的思想其实非常好理解,如下图所示,拿5个预测结果进行举例,通过组合前5个召回结果中相同类别图像的余弦相似性来作为最终结果的输出而非单纯的使用最相近的单张图片。在通过交叉验证的过程中,发现组合最好的函数为8次方然后求和,即在求和前先对每个分数应用8次方函数,可以参照下图对该过程有一个更直观的理解。
Fig.3 soft-voting
3.3 Lofter+RANSAC
如果要获得最佳的图像检索结果,学术界认为往往要同时依据全局特征和局部特征去进行检索,然而由于依据局部特征的检索方法往往时间效率很差,因此最终方案将其放置在了精排序的部分,即首先依据最初的全局特征进行了Top10的召回,然后再进行局部特征维度上的检索。

Fig.4 原始图像
关于局部特征的匹配,通用的流程是建立图像级别的描述算子,然后进行搜索匹配描述算子,本次比赛尝试了两套算法流程分别是SuperPoint[11]+SuperGlue\[12]+RANSAC和CVPR2021的提出的Lofter[13]+RANSAC算法,Lofter的优势在于其提出了一种新颖的用于局部图像特征匹配的方法。代替了传统的顺序执行图像特征检测,描述和匹配的步骤,Lofter算法首先在粗粒度上建立逐像素的密集匹配,然后在精粒度上完善精修匹配的算法。然后使用Transformers中的自我和交叉注意力层(self and cross attention layers)来获取两个图像的特征描述符。RANSAC算法通过反复选择数据中的随机子集来拟合直线,从而完成对样本对的筛选,删除异常值。

Fig.5 Lofter+RANSAC
3.4 Lightgbm re-rank strategy
Fig.6 Lightgbm re-rank pipeline
通过上述的几种re-rank方法的组合使用,到这个阶段重新从Top10中选取了Top5的图片,除此之外,还拥有了多种不同的特征比如:ransac inliers, similarity to index images, similarity to non-landmark images etc. 这些特征都可以用来构建一个机器学习模型来决定一张图片所属类别或者是否为地标图片。将label 设置为0-6的7个数字,其中0-4表示检索得到的第Topk个值为ground truth,5为该图片为非地标图片,6为该图片含有地标,但召回前5项没有其对应的ground truth。在此基础上进行机器学习模型的训练,得到最终类别的概率得分并且输出目标结果,通过上述方法可以有效的对非地标干扰图像进行降权,从而有效地提高Gap指标。
4 结论
本文主要介绍了在谷歌地标检索比赛中所中使用的方案,包括模型选型、数据增强、训练流程、精排序策略等等,其中不乏一些最新的模型和算法的应用和实践。最终上述这套流程在同各路参赛团体包括国外企业学校:nvidia rapis ai,H2O,微软,剑桥大学,莫斯科国立大学等以及国内的阿里巴巴算法团队和字节跳动视觉团队等中脱颖而出获得检索和细粒度图像识别双赛道金牌。
参考文献

更多推荐


 0
0 0
0- 0



 已为社区贡献77条内容
已为社区贡献77条内容

所有评论(0)