
视觉里的生成式自监督学习
本文主要介绍生成式自监督学习方法,MAE 表现优秀,在只使用 ImageNet-1K 数据集,通过 pretrain + fine-tune 进行模型训练,Backbone 使用 ViT-B 模型。
摘要
自监督学习(Self-Supervised Learning),是无监督学习里面的一种,主要是希望能够学习到一种通用的特征表达用于下游任务 (Downstream Tasks)。NLP 领域自监督学习方法比较成熟,近期 CV 领域也出现一些表现优秀的自监督学习方法。自监督学习能很好的解决现在大量无标签数据以及数据标注成本高的问题。Yann Lecun 也在 AAAI 上讲 自监督学习是未来的大势所趋。
视觉自监督学习主要分两种:判别式和生成式。判别式依赖于强大的数据增强方法,使用不同的数据增强方法生成两种数据,通过对比学习训练两种数据学习视觉的通用表达;生成式不需要很强的数据增强方法,使用掩码掩盖部分图像,通过预测被掩盖的图像学习视觉的通用表达。本文主要介绍生成式自监督学习方法,MAE 表现优秀,在只使用 ImageNet-1K 数据集,通过 pretrain + fine-tune 进行模型训练,Backbone 使用 ViT-B 模型,准确率可以达到 83.6% 。
1 背景
近些年,计算机硬件快速发展,OpneAI、英伟达等公司已经完成千亿级模型训练。模型越大需要的数据量越大,大模型在小数据集上很容易过拟合,带标签的大数据集是非常昂贵的,并且有时候无法获得标签。在 NLP 领域通过自监督预训练成功解决了这种数据的需求。比如基于自回归语言的 GPT 模型[1][2][3]和 mask autoencoding BERT[4],在概念上很简单:删除一部分数据并学习预测删除的内容。这些方法可以训练泛化能力强的千亿参数量 NLP 模型[3]。
早期视觉领域主要以 CNN 为主,随着谷歌提出 ViT [5]框架,Transformer [6]在视觉领域有了越来越多的应用,并且各个方面都是 SOTA 表现。有实验验证表明 [7],基于 Transformer 框架的网络比 CNN 网络需要更多的数据。为了解决大模型对数据量需求大的问题,使用自监督学习解决大规模无标签图像数据是一个很好的解决方案。
NLP 领域广泛使用 Transformer 结构,自监督学习逐渐开始在 NLP 领域应用。CV 领域受 NLP 领域启发,逐渐将 NLP 的各项技术迁移到 CV 领域。视觉自监督学习主要分两种,一种是生成式,另外一种是判别式。如图1所示为两种方法示意图。基于生成式的方法主要关注重建误差,比如对于 NLP 任务而言,一个句子中间盖住一个 token,让模型去预测,将得到的预测 token 与真实的 token 作为损失;在 CV 领域会使用掩码方式覆盖部分图像,使用 Decoder 预测这些被覆盖的图像;基于对比式的方法不要求模型能够重建原始输入,而是希望模型能够在特征空间上对不同的输入进行分辨。基于对比式的方法要尽可能保证两次输入数据有区别,其效果很大程度上依赖于数据增强方法[8][9][10]。

Fig.1 生成式与判别式示意图
2 生成式自监督学习
近半年出现了许多生成式自监督学习方法,目前现有的生成式自监督方法效果优于对比式自监督学习方法。生成式自监督学习目前主要有两类:一类是预测 token;另外一类是预测 pixel。如 BEIT[11]是预测 token 的方法,BEIT 是把 BERT 迁移到 CV 领域,是 CV 领域的 BERT ,并且取得了 SOTA 表现;预测 pixel 方法有很多,如 MAE[12] 、PeCo[13] 和 SimMIM[14]等方法,限于篇幅,关于预测 pixel 方法仅介绍 MAE,其优势在于既有 SOTA 表现又能节省计算资源。
2.1 预测 token 的生成式自监督学习
BEIT 是 CV 领域的 BERT ,训练好的 BERT 模型相当于是一个 Transformer 的 Encoder,它能够把一个输入的句子进行编码,得到一堆 tokens。BEIT 则是把输入的图像进行编码,得到一堆向量,并且这些向量结合了图像的上下文。
2.1.1 技术点
图像表达
在 BEIT 算法中,图像有两种形式: image → image patches | visual tokens,在预训练的过程中,它们分别被作为模型的输入和输出,如下图2所示。

Fig.2 BEIT 图像两种表示
1. 将图片表示为 image patches:
将图片表示为 image patches 这个操作和 Vision Transformer 对图片的处理手段是一致的。首先把 ![]() 的图像分成
的图像分成 ![]() 个展平的 2D 块
个展平的 2D 块![]() 。
。
式中,C是 channel 数,(H,W)是输入的分辨率,(P,P)是块大小。每个 image patch 会被展平成向量并通过线性变换操作 (flattened into vectors and are linearly projected)。这样一来,图像变成了一系列的展平的 2D 块的序列,这个序列中一共有 ![]() 个展平的 2D 块,每个块的维度是
个展平的 2D 块,每个块的维度是![]() 。实际操作时P=16, H=W=224,和 ViT 一致。
。实际操作时P=16, H=W=224,和 ViT 一致。
2. 将图片表示为 visual tokens:
BEIT 通过使用 image tokenizer,把一张图片 ![]() 变成离散的 tokens
变成离散的 tokens![]() 。字典
。字典 ![]() 包含了所有离散 tokens 的索引。
包含了所有离散 tokens 的索引。
BEIT 里的 dVAE:tokenizer 和 Decoder
BEIT 训练了一个离散变分自编码器(discrete variational autoencoder)。训练的过程如下图3所示。dVAE 虽然是离散的 VAE,但它和 VAE 的本质还是一样的,都是把一张图片通过一些操作得到隐变量,再把隐变量通过一个生成器重建原图。dVAE 中的 Tokenizer 就相当于是 VAE 里面的均值方差拟合神经网络,dVAE中的 Decoder 就相当于是 VAE 里面的生成器。
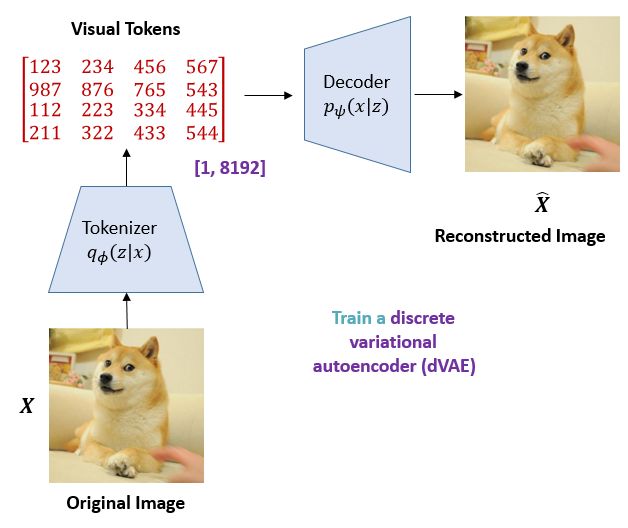
Fig.3 dVAE 训练过程
2.1.2 BEIT 结构
BEIT 的总体结构如下图4所示,BEIT 的结构可以看成两部分,分别是:BEIT Encoder 和 dVAE。BEIT 的 Encoder 结构就是 Transformer 的 Encoder,模型架构是一样的。图片在被分成![]() 个展平的 2D 块
个展平的 2D 块 ![]() 之后,通过线性变换得到
之后,通过线性变换得到 ![]() ,其中
,其中![]() 。再接上一个 special token [S]。BEIT 还给输入加上了 1D 的位置编码
。再接上一个 special token [S]。BEIT 还给输入加上了 1D 的位置编码![]() ,所以总的输入张量可以表示为:
,所以总的输入张量可以表示为:![]() 。
。
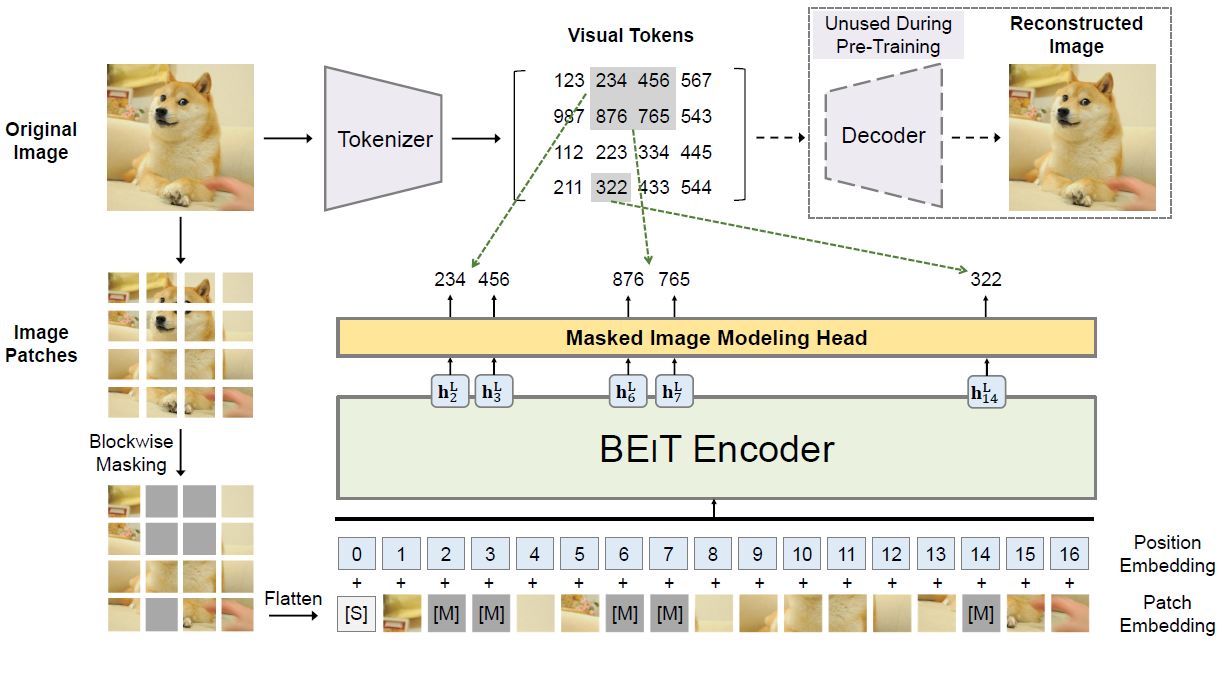
Fig.4 BEIT 整体结构
输入 BEIT 的 Encoder 之后,张量依次通过 L$个 Encoder Block:![]()
式中 l=1,2,...,L。最后一层输出![]() 作为 image patches 的 encoded representations,代表第i个 image patch 的编码表示。
作为 image patches 的 encoded representations,代表第i个 image patch 的编码表示。
BEIT 遵循 BERT 的训练方法,让 BEIT 看很多的图片,随机盖住一些 image patches,让 BEIT 模型预测盖住的 patches ,不断计算预测的 patches 与真实的 patches 之间的差异,利用反向传播更新参数,最后达到自监督训练的效果。
不同的是,BERT 的 Encoder 输入是 token,输出还是 token,让盖住的 真实 token 与预测输出 token 越接近越好;而 BEIT 的 Encoder 输入是 image patches,输出是 visual tokens,让盖住的位置输出的 visual tokens 与真实的 visual tokens 越接近越好。
2.1.3 实验结果
分类实验
BEIT 将预训练模型在小数据集上进行 fine-tune。分类实验使用 CIFAR-100 和 ImageNet-1k 这两个数据集,超参数设置如下图5所示:
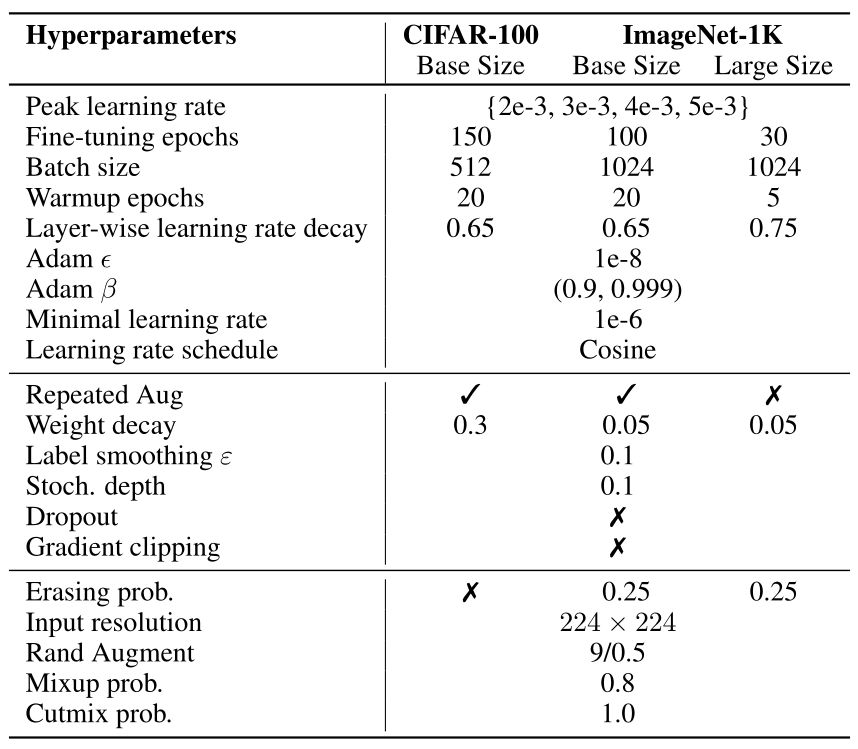
Fig.5 CIFAR-100 和 ImageNet-1k 超参数
图6是 BEIT 在 CIFAR-100 和 ImageNet-1k 数据集上的实验结果。所有模型都使用 ViT-B 。与随机初始化训练的模型相比,预训练的 BEIT 模型在两种数据集上的性能都有显著提高。在较小的 CIFAR-100 数据集上,从头训练的 ViT 仅达到 48.5\% 的准确率。相比之下,通过 pretrain 的帮助,BEIT 达到了90.1\%。BEIT 可以大大降低标签数据的需求。

Fig .6 BEIT 在 CIFAR-100 和 ImageNet-1k这两个数据集上的性能以及与其他模型的对比
BEIT 与 21 年几个最先进的 Transformer 自监督方法(如 DINO , MoCo v3)进行了比较,在 ImageNet-1k 微调上优于以往的模型。在 ImageNet-1k 上的表现优于 DINO,在 CIFAR-100 上优于 MoCo v3。
BEIT 使用 pretrain + fine-tune 的范式在 ImageNet-1k 数据集上做了实验。以自监督的方式对 BEIT 进行预训练,然后用标记数据在 ImageNet-1k 上对预训练的模型进行 fine-tune。结果表明,在 ImageNet-1k 上进行 Intermediate fine-tune 后会获得额外的增益。
BEIT 在 384×384 高分辨率数据集上面做 fine-tune 10 个 epoch ,同时 patch 的大小保持不变。结果如下图7所示,在 ImageNet-1k 上,高分辨率图像可以提高 1 个点的测试集准确率。当使用相同的输入分辨率时,用 ImageNet-1K 进行预训练的 BEIT-384 比使用 ImageNet-22K 进行监督预训练的 ViT-384 效果好。
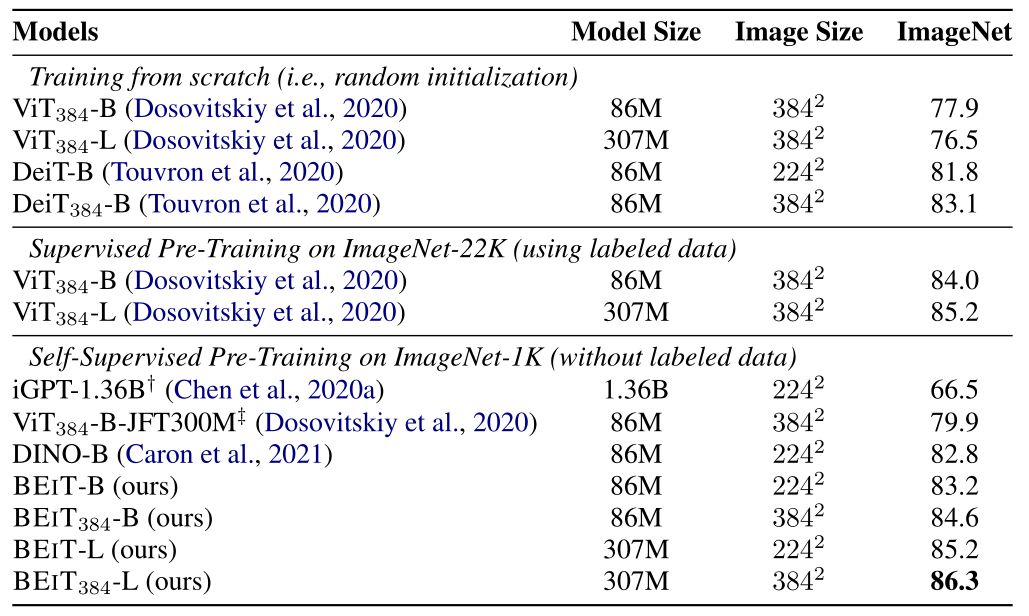
Fig.7 Top-1 accuracy on ImageNet-1K
BEIT 使用 ViT-L Backbone 进行实验测试,结果如上图7所示,在 ImageNet-1k 上,从头开始训练时,ViT-384-L 比 ViT-384-B 差。结果验证了 Vision Transformer 模型对数据量需求大的问题。解决方法就是用更大的数据集 ImageNet-22K。BEIT-L 比 BEIT-B 测试集准确率高 2 个点,说明大数据集对 BEIT 的帮助更大。
2.2 预测 pixel 的生成式自监督学习
近期何恺明团队发布了 MAE 这篇文章,MAE 是最新的视觉自监督 SOTA 结果。MAE 整篇文章思路比较简单但是表现非常好,通过盖住图像中的部分图像,让模型去预测,将预测的结果与真实的 image patches 的误差作为损失。直接重建原图并且表现非常好。
2.2.1 技术点
mask 方式
MAE 采用了不同的 mask 方式做对比实验,一共采用了三种 mask 方式:random masking、block-wise masking 以及 grid-wise masking。同时对 mask 比例做了研究,如图8所示,block-wise masking 在 mask 50%时的效果不错,但是当 mask 比例达到75%时性能就大幅下降了。grid-wise sampling 使得任务变得更简单,但相应的,图像重建质量也下降了。 简单的随机抽样最适合 MAE 模型。图9显示了不同 mask 方法图像重建结果。

Fig.8 mask 方式. random 方式效果最好

Fig.9 不同 mask 采样策略的影响
mask 比例
如下图10所示代表了 masking ratio 对结果的影响。最优的 masking ratio 出乎意料地高,当 masking ratio=75% 时,linear probing 和 fine-tune 的性能依旧很好。 这种行为与 BERT 相反,BERT 的典型 masking ratio 只有15%。从这个结果可以得出结论:MAE 自监督训练好的模型可以推断出缺失的 patch 。

Fig.10 masking ratio对结果的影响
图10显示了 linear probing 和 fine-tune 的性能随着 masking ratio 改变的变化趋势。对于 fine-tune,40-80% 的 masking ratio 表现都很好。
自监督学习目标函数
Decoder 的最后一层是一个 Linear Projection 层,其输出的 channel 数等于图像的像素 (pixel) 数。 Decoder 的输出会进一步 reshape 成图像的形状。损失函数是 MSE Loss,即直接让重建图像和输入图像的距离越接近越好。在计算 MSE Loss 时,只计算被 mask 的部分,将计算量减小为原来的 3/4 。
MAE 进行了另外一种损失函数的实验,先计算出每个 patch 的像素值的均值和方差,使用它们去归一化这个 patch 的每个像素值。最后再使用归一化的像素值进行 MSE Loss 计算。发现这样做的效果比直接 MSE Loss 好。
2.2.2 MAE 结构
MAE 方法属于一种去噪自编码器 (Denoising Auto-Encoders (DAE)),去噪自动编码器是一类自动编码器,它破坏输入信号,并学会重构原始、未被破坏的信号。MAE 的 Encoder 和 Decoder 结构不同,是非对称式的。Encoder 将输入编码为 latent representation,而 Decoder 将从 latent representation 重建原始信号。图11为 MAE 框架图。
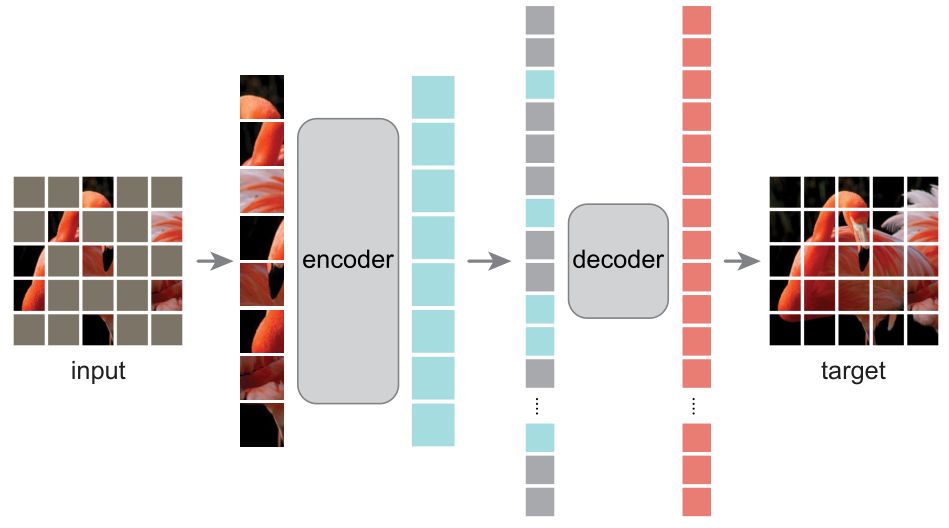
Fig.11 MAE 结构框架
MAE 和 ViT 的做法一致,将图像划分成规则且不重叠的 patches。然后随机选择一些 patches 然后进行 mask 操作。MAE 使用 很高的 masking ratio ,大大减小了图像的冗余信息。
MAE Encoder
MAE Encoder 采用 ViT 架构,其输入是 unmasked patches。MAE Encoder 先通过 Linear Projection 进行图像编码,再加上位置编码,输入进连续的 Transformer Block 里。MAE Encoder 只对整个图像的部分 patches 进行操作,删除 masked patches。该做法与 BERT 不一样,BERT 对于 mask 掉的部分使用特殊字符, MAE 不使用掩码标记。
MAE Decoder
MAE Decoder 采用 Transformer 架构,输入图像 patches 集合。每个 mask tokens 都是一个共享的、学习的向量。
MAE Decoder 仅用于预训练期间图像重建。自监督学习只用最后预训练好的 Encoder 完成分类任务。因此,可以灵活设计与 Encoder 无关的 Decoder 。MAE 使用比 Encoder 更小的 Decoder 进行实验。 使用非对称的设计,tokens 可以由轻量级 Decoder 处理,大大缩短了预训练时间。
2.2.3 实验结果
分类实验
MAE 使用 ViT-Large (ViT-L/16) 作为 Encoder Backbone,对比结果如下图12所示:
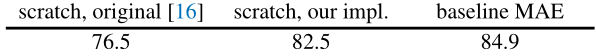
Fig.12 ImageNet-1k 实验结果
- 76.5 是 ViT 论文 Backbone 使用 ViT-Large ,在 ImageNet-1k 进行监督学习训练结果;
- 82.5 是何恺明团队自己复现的实验结果,Backbone 使用 ViT-Large ,使用 ImageNet-1k 数据集进行监督学习训练结果;
- 84.9 是 MAE 自监督训练的结果,Backbone 使用 ViT-Large ,在 ImageNet-1k 数据集上进行 pretrain + fine-tune ,其准确率高于监督学习的 82.5。
如下图13所示为不同自监督方法性能对比,对于 ViT-B 模型,所有自监督方法性能相差不大,但对于更大的 ViT-L 模型,MAE 性能要优于其他自监督学习方法,表明 MAE 对于大模型具有更好的泛化性能。

Fig.13 不同自监督方法性能对比
使用 ViT-H 结构的 Encoder,经过 fine-tune 之后准确率可以到 86.9% ,使用 448X448 分辨率图像进行 fine-tune,准确率可以到 87.8%,该训练过程只使用 ImageNet-1k 数据集。
与 BEiT 相比,MAE 训练速度更快,训练方式更简单。图13中的模型为预训练 1600 epoch 的模型。在同样的硬件条件下训练,MAE 总的训练时间比其他任何自监督学习方法都短。例如,同样使用128个 TPU-v3,Backbone 使用 ViT-L,MAE 训练1600个 epoch 需要花费31个小时。MoCo v3 训练300个 epoch 需要花费36个小时。
3 总结与展望
视觉自监督学习是未来发展的趋势,通过自监督学习解决大规模无标签数据是一个有效的方法。使用 pretrain + fine-tune 的训练方法也是目前公认的范式,通过 pretrain 学习到很好的图像表征一直都是研究热点。在训练大模型时计算资源会相对比较紧张,节省内存也变得格外重要,业界在追求既 SOTA 又节省计算资源的训练方法。上述方法都是通过 mask 然后去预测,最后的效果都非常好。从 MLM 到 MIM 的过渡已被证明,比肩 GPT3 的 CV 预训练大模型指日可待。
参考文献

更多推荐


 0
0 0
0- 0



 已为社区贡献77条内容
已为社区贡献77条内容

所有评论(0)